【学界】机器学习模型的“可解释性”到底有多重要?
来源:专知
【导读】我们知道,近年来机器学习,特别是深度学习在各个领域取得了骄人的成绩,其受追捧的程度可谓是舍我其谁,但是有很多机器学习模型(深度学习首当其冲)的可解释性不强,这也导致了很多论战,那么模型的可解释性到底有多重要?本文从各方面介绍了机器学习模型的“可解释性”的重要性,说明我们为什么要追求可解释性,并在几种典型的模型中,如广义线性模型、随机森林和深度学习,说明其重要性。

Interpreting machine learning models
无论您的解决方案的最终目标是什么,终端用户都需要可解释、可关联或可理解的解决方案。此外,作为一名数据科学家,您将总能从模型的可解释性中受益,从而验证并改进您的工作。在这篇博客文章中,我试图说明机器学习中可解释性的重要性,并讨论一些可以自己尝试的简单实验和框架。

https://xkcd.com/1838/
为什么机器学习中的可解释性很重要?
在传统统计中,我们通过调查大量的数据来构造和验证假设。我们建立模型来构建规则,我们可以将其纳入我们的模型中。例如,营销公司可以建立一个模型,将营销活动数据与财务数据相关联,以确定构成有效营销活动的是什么。这是一种自上而下的数据科学方法,可解释性是关键,因为它是所定义规则和过程的基石。由于相关性往往不等于因果关系,所以在进行决策和解释时,需要对模型进行很强的理解。
在自下而上的数据科学方法中,我们将部分业务流程委托给机器学习模型。此外,全新的商业创意可通过机器学习实现。自下而上的数据科学通常将手动和部分困难任务自动化。例如制造公司可以将传感器放在他们的机器上并进行预测维护。因此,维护工程师可以更高效地工作,而无需执行昂贵的定期检查。模型可解释性对于验证模型的行为是否符合您的期望是很有必要的,并且它可以与用户建立信任关系,并且可以简化从手动过程到自动化过程的过渡。
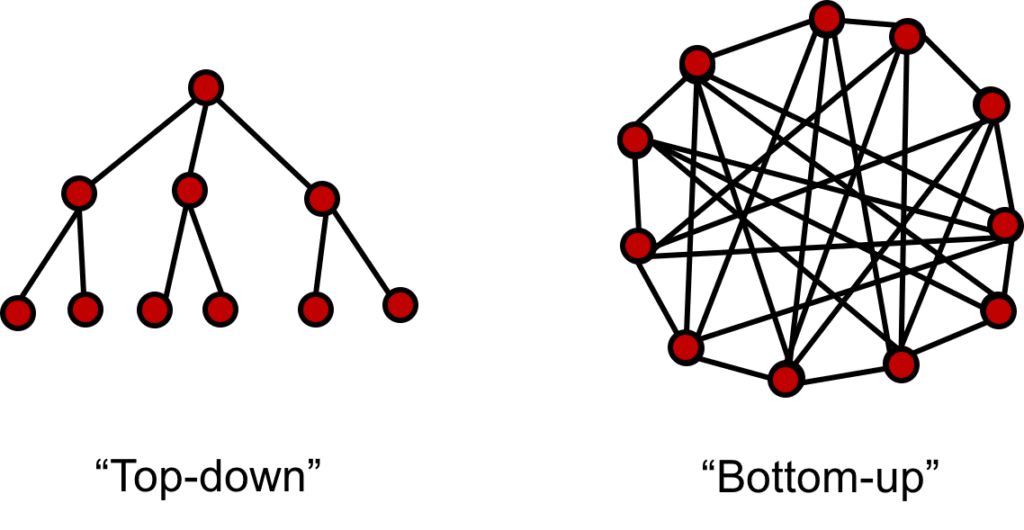
图显示在一个自上而下的过程中,您迭代地构造和验证一组假设。在自底向上的方法中,您试图自动化过程从自底向上解决问题。
作为一名数据科学家,您经常关心微调模型以获得最佳性能。数据科学通常被定义为:'给出具有X标签的数据,并以最小误差找到模型'。尽管训练高性能模型的能力对于数据科学家来说是一项关键技能,但能够从更大的角度来看是很重要的。数据和机器学习模型的可解释性是在数据科学的 “有用性”中至关重要的方面之一,它确保模型与您想要解决的问题保持一致。尽管在构建模型时尝试最前沿的技术可能会有很多挑战,但能够正确地解释您的发现是数据科学过程的重要组成部分。

为什么深入分析模型至关重要?
作为数据科学家,关注模型可解释性有几个原因。虽然它们之间存在重叠,但能捕捉到可解释性的不同动机:
1.判别并减轻偏差(Identify and mitigate bias):
偏差可能存在于任何数据集中,数据科学家需要确定并尝试修正偏差。数据集的规模可能有限,并且不能代表所有数据,或者数据捕获过程可能没有考虑到潜在的偏差。在彻底进行数据分析后,或者分析模型预测与模型输入之间的关系时,偏差往往会变得明显。请注意,解决偏差问题没有唯一的解决方案,但是可解释性的关键一步是意识到潜在的偏差。
其他偏差的例子如下:
例如word2vec向量包含性别偏差(http://wordbias.umiacs.umd.edu/),这是由于他们受过训练的语料库中存在的内在偏差。当你使用这些词向量进行训练模型时,招聘人员搜索“技术简介”将使女性履历保留在最下面。
例如当您在小型数据集上训练目标检测模型时,通常情况下图像的宽度太有限。为了避免只适用于数据中噪音和不重要元素的模型,需要在不同环境,不同光照条件和不同角度下的各种物体图像。
2.考虑问题的上下文(Accounting for the context of the problem):
在大多数问题中,您正在使用的数据集仅仅是您正试图解决的问题的粗略表示,而机器学习模型无法捕捉到真实任务的完整复杂性。可解释模型可帮助您了解并解释模型中包含和未包含的因素,并根据模型预测采取行动时考虑问题的上下文情境。
3.改进泛化能力和性能(Improving generalisation and performance):
高解释性模型通常有更好的泛化能力。可解释性不是要了解所有数据点的模型的每个细节。必须将可靠的数据,模型和问题理解结合起来才能获得性能更好的解决方案。
4.道德和法律原因(Ethical and legal reasons):
在财务和医疗保健这样的行业,审计决策过程并确保它是没有歧视或违反任何法律。随着数据和隐私保护法规(如GDPR)的发展,可解释性变得更加重要。此外,在医疗应用或自动驾驶汽车中,单一不正确的预测会产生重大影响,能够“验证”模型至关重要。因此,系统应该能够解释它是如何达到给定的要求的。
解释你的模型
关于模型可解释性的通常引用是,随着模型复杂性的增加,模型可解释性按照同样的速度降低。特征重要性是解释模型的一种基本方法。即使对于深度学习等黑盒模型,也存在提高可解释性的技术。最后,将讨论LIME框架,该框架可作为模型分析的工具箱。
特征重要性(Feature importance)
• 广义线性模型
广义线性模型(GLM's)都基于以下原则:如果将特征与模型权重进行线性组合,并通过一个函数 f得到结果,则可以用它来预测各种各样的响应变量。 GLM最常见的应用是回归(线性回归),分类(logistic回归)或建模泊松过程(泊松回归)。训练后得到的权重能直接表示特征重要性,它们提供了内部模型非常具体的解释。
例如在构建文本分类器时,可以绘制最重要的特征,并验证模型是否过拟合。如果最重要的单词不符合您的直觉(例如名称或停用词),则意味着该模型拟合了数据集中的噪音,将在新数据中表现不佳。
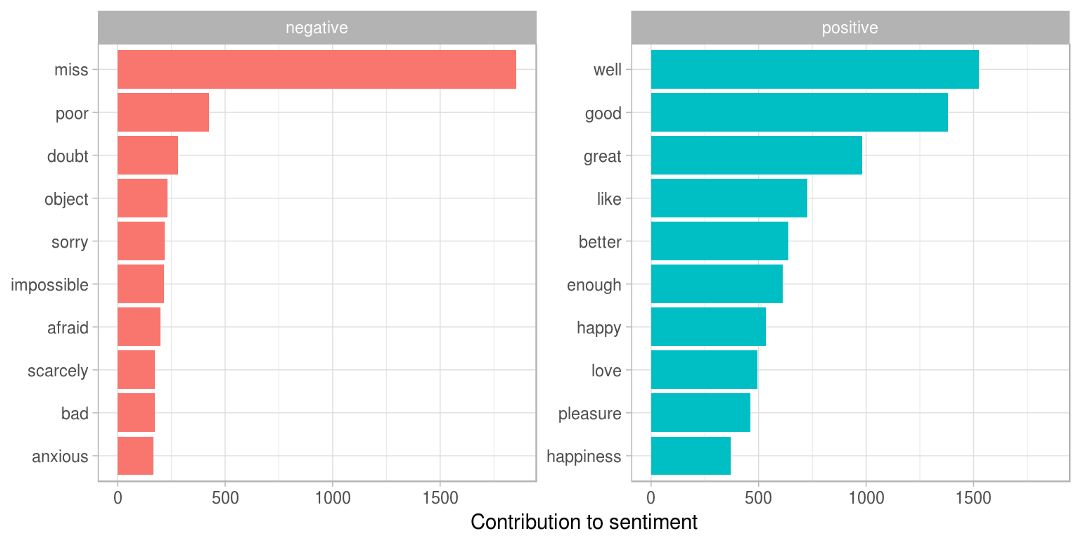
从TidyTextMining的文本解释能力的一个可视化的示例。
https://www.tidytextmining.com/02-sentiment-analysis_files/figure-html/pipetoplot-1.png
· 随机森林和SVM(Random forest and SVM’s)
即使是非线性模型(如基于树的模型(例如随机森林))也能够获取关于特征重要性的信息。基于核的方法(如SVM)中的权重通常不是特征重要性的很好的代表。核方法的优点在于,通过将特征投影到内核空间中,您可以捕获变量之间的非线性关系。另一方面,仅将权重视为一个特征,与交互无关。
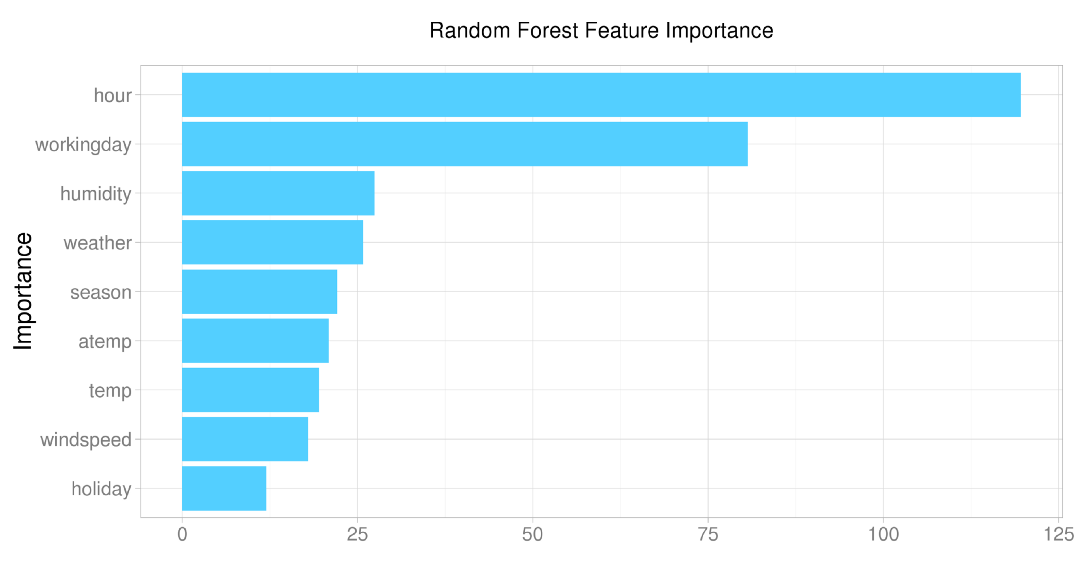
图显示一个使用特征重要性可视化出的例子,图中您可以确定模型在学习什么。由于这个模型中很多重要的特征都是指这一天day的信息,所以可能需要添加额外的基于时间的特征会使其效果更好。(Kaggle)
https://www.kaggle.com/general/13285
· 深度学习(Deep learning)
深度学习模型由于参数的数量以及提取和组合特征的复杂方法而导致其不可解释性。作为一类模型,它能够在许多任务中获得最好的性能,许多研究集中在将模型预测与输入相关联。
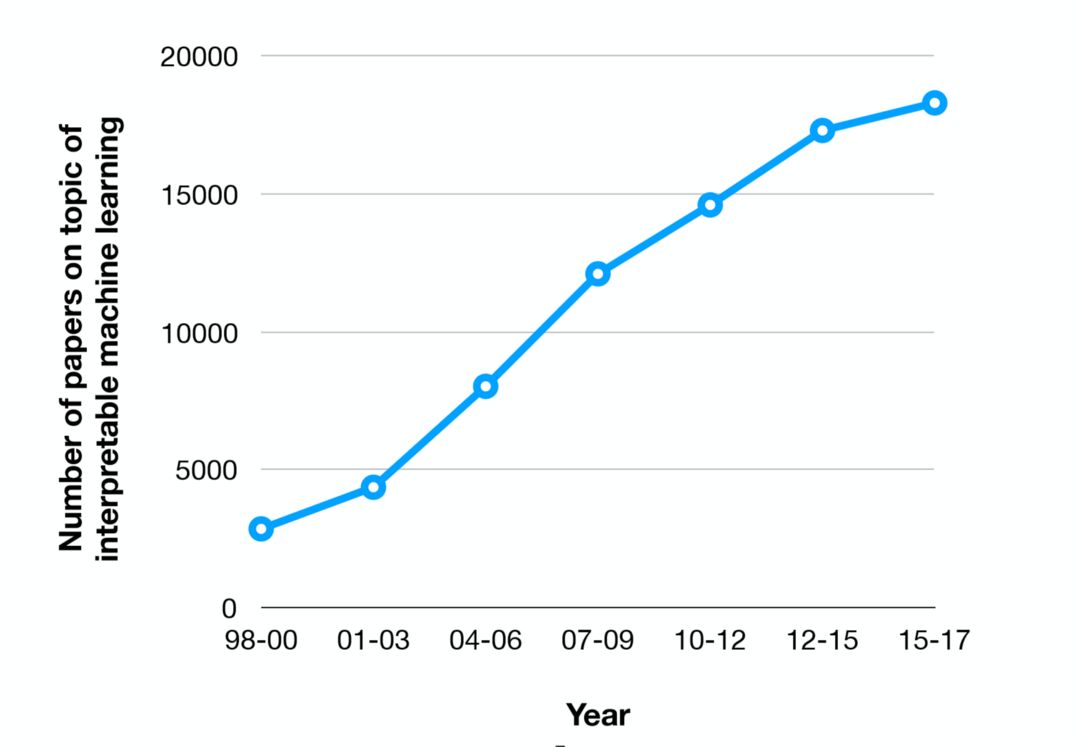
可解释机器学习的研究论文的数量正在迅速增长(MIT)。
http://people.csail.mit.edu/beenkim/papers/BeenK_FinaleDV_ICML2017_tutorial.pdf
特别是在面向更复杂地文本和图像处理的系统时,很难解释模型实际学到的是什么。研究的主要焦点目前主要是将输出或预测与输入数据关联。虽然在线性模型下这相当容易,但对于深度学习网络来说,它仍然是一个未解决的问题。两种主要方法是基于梯度或基于注意力机制的。
在基于梯度的方法中,使用反向传播计算目标概念的梯度用于生成一个映射,以突出显示输入中用于预测目标概念的重要区域。这通常应用于计算机视觉领域。
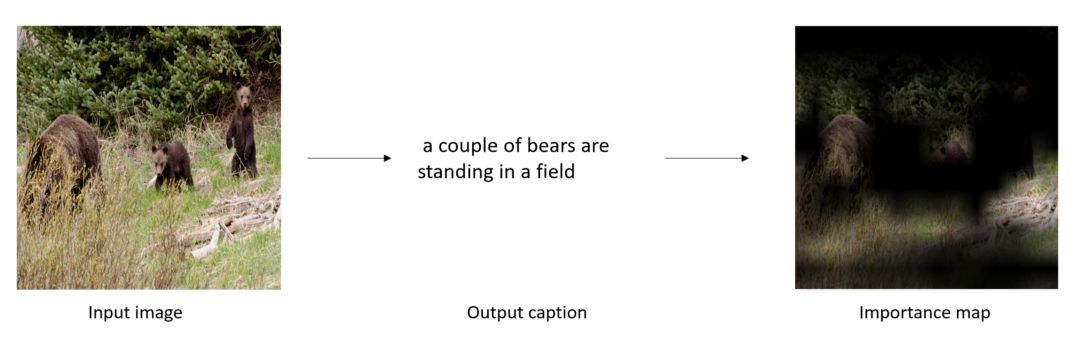
Grad-CAM, 一个基于梯度的方法被使用于视觉描述生成。基于输出的文字,方法能够判别出输入图像的那个区域是重要的
基于注意力机制的方法通常与序列数据(例如文本数据)一起使用。除了网络的正常权重之外,注意力权重被训练成 ‘input gates’。这些注意力权重决定最终网络输出中每个不同元素的数量。除了可解释性之外,在基于文本的“问答系统”中也可以带来更好的结果,因为网络能够“关注”其注意力。

在基于注意力机制的自动问答中,可以可视化出文本中哪个单词对于这个问题的答案是最最重要的。
LIME
LIME是一个更通用的框架,旨在使“任何”机器学习模型的预测更加可解释。
代码链接:https://github.com/marcotcr/lime
为了保持模型独立性,LIME通过修改本地模型的输入来工作。因此,它不是试图同时理解整个模型,而是修改特定的输入实例,并监控对预测的影响。在文本分类的情况下,这意味着一些词被取代,以确定哪些元素的输入影响了预测。
参考文献:
https://towardsdatascience.com/interpretability-in-machine-learning-70c30694a05f
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【征稿通知】IEEE IV 2018“智能车辆中的平行视觉”研讨会
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【最全解读】从原理到代码,Hinton的胶囊网络实用指南(附视频+代码)
☞【业界】OpenAI发布8个仿真机器人环境和HER实现:可用于训练实体机器人模型
☞【深度】走进深度生成模型:变分自动编码器(VAE)和生成对抗网络(GAN)




