NIPS 2018 | 轨迹卷积网络 TrajectoryNet
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者:林天威
来源:https://zhuanlan.zhihu.com/p/51550622
原文:http://bbs.cvmart.net/articles/272
行为识别(视频分类)是视频理解领域非常重要的一个方向。在深度学习之前,效果最好的行为识别方法是iDT(改进的密集轨迹方法),即先在图像中生成密集的轨迹,再沿着轨迹提取特征,从而获得视频整体的编码。而在深度学习时代,占主流地位的则为两类方法,一是双流网络,用两个子网络分别对图像和光流进行卷积,再进行融合;二是3D卷积网络,直接将视频帧序列的时序看作一个维度进行卷积。基于轨迹的方法在TDD[4] 算法后就好几年没有新的工作了。在最近的NIPS18会议上,CUHK的Yue Zhao 和Yuanjun Xiong大佬提出了一种新的卷积方式——轨迹卷积,并提出了端到端的轨迹卷积网络[1],这篇笔记就主要介绍这篇文章。
方法回顾
如刚刚介绍,现有的深度学习行为识别方法大致可以分为双流网络和3D卷积网络。近两年大量3D卷积网络地工作主要针对如何增加3D网络容量、降低3D网络计算开销、更好地进行时序关联和建模等问题进行了研究。其中,很多方法采取的思路是将3D卷积分解为2D空间卷积加上1D的时序卷积,如Separable-3D(S3D)[7] 、R(2+1)D[8]等等。但这篇文章认为,直接在时间维度上进行卷积隐含了一个很强的假设,即认为帧间的特征是很好地对齐地,而事实上人或者物体在视频中可能存在着很大地位移或是形变。因此,作者认为沿着轨迹来做时序上的卷积是更合理的方式。
这里再回顾一下几篇经典的基于轨迹的方法——DT[2] , iDT[3] , TDD[4]。DT算法[2]的框架图如下图所示,包括密集采样特征点,特征点轨迹跟踪和基于轨迹的特征提取几个部分。后续的特征编码和分类过程则没有在图中画出。
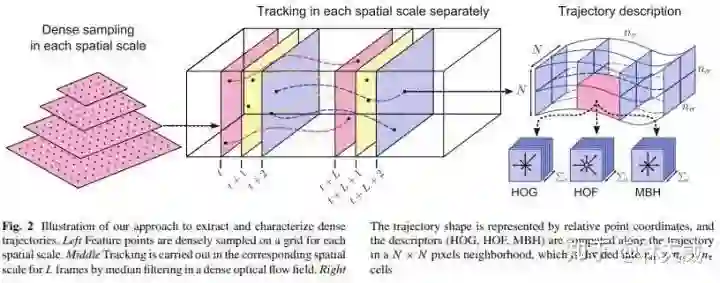
之后,DT算法的作者又进行了算法改进,提出了iDT[3]算法。iDT算法则主要是增加了视频帧间的对齐,从而尽可能地消除相机运动带来的影响。在DT和iDT方法中,采用的都还是人工设计的传统特征,而在深度学习流行后,Yuanjun Xiong前辈提出了TDD[4]算法,如下图所示,主要是将iDT算法中的传统特征替换为了深度学习的特征,获得了一定的效果提升。
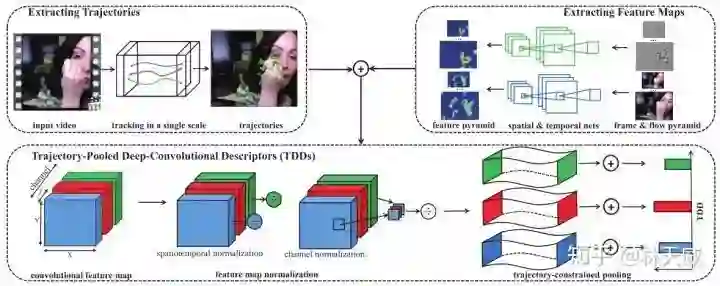
虽然轨迹类的方法符合人类对视频的直观理解,但此前的这几种轨迹方法都存在着比较大的缺陷从而难以获得更好的应用:首先在这些方法中,轨迹的提取以及特征的提取是独立的过程,一方面在实现是比较繁琐,另外一方面也不能够进行端到端的学习;其次,这些方法最后都依赖于Fisher Vector或VLAD编码,通常会产生非常高维的特征向量,在储存和计算等方面效率都比较差。因此,最近几年基本上没有啥新的轨迹类方法。
这篇轨迹卷积网络则主要受到可变形卷积网络DCN[5] 的启发。可变形卷积网络如下图所示,通过网络学习每次卷积的offset,来实现非规则形状的卷积。而在轨迹卷积网络中,则是在时序上将轨迹的偏移向量直接作为可变形卷积的offset,从而实现了轨迹卷积。

方法介绍
轨迹卷积
本文的一个主要贡献就是提出了轨迹卷积层。如下图所示,传统的3D卷积或是时序卷积在时序方向上的感受野是对齐的,而轨迹卷积则按照轨迹的偏移在时序上将卷积位置偏移到对应的点上去,从而实现沿着轨迹的卷积。此处具体的公式表达可见论文。
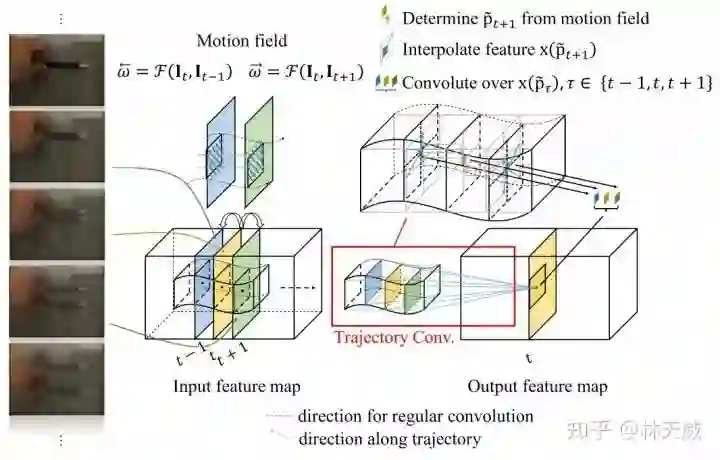
那么,如何实现轨迹卷积呢?作者提出可以将轨迹卷积看作是3D可变形卷积的一个特定例子。具体而言,卷积核的大小定义为3 x 1 x 1,即沿着时序卷积,偏移量方面则将时序偏移设置为0,只考虑空间上的偏移。与可变形卷积网络不同的是,轨迹卷积中的空间偏移量并不是通过网络学习得到,而是设定为相邻帧之间轨迹的偏移量。因此,基于可变形卷积网络的代码,轨迹卷积是非常易于实现的。
表观及运动特征结合
轨迹卷积实际上是沿着运动方向对表观特征进行结合,作者认为这样的方式对运动信息的表达还不够。参考DT算法的思路,可以直接将轨迹偏移量信息作为特征。在这篇文章中,作者则将轨迹的偏移量图直接和原始的表观特征图进行了堆叠,从而进行了信息的融合。这样的融合方式比起双流网络中late fusion的方式要更高效和自然一些。此处的轨迹偏移量图为降采样的运动场图(比如光流图)。
网络结构
网络结构方面,轨迹卷积网络直接将Separable-3D网络( ResNet18 architecture)里中层的1D时序卷积层替换为了轨迹卷积层。
轨迹的学习
本文中所采用的密集轨迹通常是通过光流的方式呈现。光流的提取有很多方式,传统的方式通过优化的方法计算光流,而近几年基于深度学习的方法则获得了很好的效果。为了能够将轨迹的生成也纳入网络一起学习,本方法采用了 @朱毅前辈提出的MotionNet[6]网络,将预训练的MotionNet和轨迹卷积网络一起训练。在此处的训练过程中,并不采用真实光流的监督信息,而是采用了[6]中提出的无监督辅助损失函数。最后的实验结果表明不采用辅助损失函数直接finetune会带来效果的降低,而添加辅助损失函数则能带来效果的上升。
实验效果
该论文在Something-Something-V1和Kinetics这两个大规模视频分类数据集上进行了实验,并比起baseline(S3D) 获得了一定的效果提升。具体效果如下图所示。


从结果可以看出,基于较小的基础网络,轨迹卷积网络也获得了不错的效果,表明轨迹卷积网络的有效性。另外一方面,行为识别方法的速度也很重要,下图则展示了S3D网络以及轨迹卷积网络的单次前向速度。可以看出,目前轨迹卷积网络的速度还有较大的提升空间。

小结
这篇文章是我今年看到最喜欢的一篇行为识别论文了。其实去年自己也考虑了一段时间如何将轨迹信息完整的融入到网络中,但没想好该如何实现,虽然也读过可变形卷积的论文,可惜没有想到将两者联系起来。所以,读到Yue Zhao 的这篇文章有种豁然开朗的感觉。另外也要感叹,CUHK的mmlab在行为识别这块实力非凡,做出了很多重要的工作。总的来说,这篇文章所提出的轨迹卷积很好地将传统轨迹方法和深度学习结合在了一起,在算法效率和算法效果上则还有一定的提升空间,应该会有不少工作后续进行跟进。
参考文献
[1] Zhao Y, Xiong Y, Lin D. Trajectory Convolution for Action Recognition[C]//Advances in Neural Information Processing Systems. 2018: 2205-2216.
[2] Heng Wang, Alexander Kläser, Cordelia Schmid, and Cheng-Lin Liu. Action recognition by dense trajectories. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3169–3176. IEEE, 2011.
[3] HengWang and Cordelia Schmid. Action recognition with improved trajectories. In The IEEE International Conference on Computer Vision (ICCV), pages 3551–3558, 2013.
[4] LiminWang, Yu Qiao, and Xiaoou Tang. Action recognition with trajectory-pooled deep-convolutional descriptors. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4305– 4314, 2015.
[5] Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei. Deformable convolutional networks. In The IEEE International Conference on Computer Vision (ICCV), pages 764–773, 2017.
[6] Yi Zhu, Zhenzhong Lan, Shawn Newsam, and Alexander G Hauptmann. Hidden two-stream convolutional networks for action recognition. arXiv preprint arXiv:1704.00389, 2017.
[7] Saining Xie, Chen Sun, Jonathan Huang, Zhuowen Tu, and Kevin Murphy. Rethinking spatiotemporal feature learning: : Speed-accuracy trade-offs in video classification. In European Conference on Computer Vision (ECCV), 2018.
[8] Du Tran, HengWang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. A closer look at spatiotemporal convolutions for action recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2018.
*延伸阅读
基于弱监督的视频时序动作检测的介绍
极市干货|孙书洋 CVPR 2018论文详解:光流导向特征在视频动作识别中的应用
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~

觉得有用麻烦给个好看啦~



