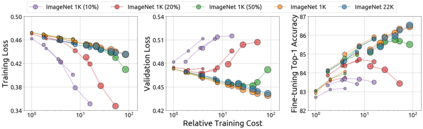
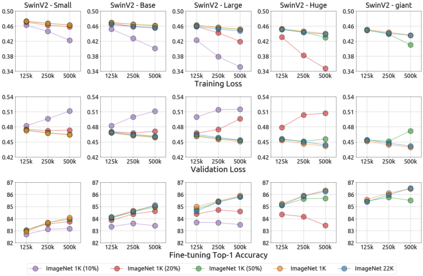
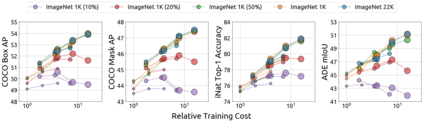
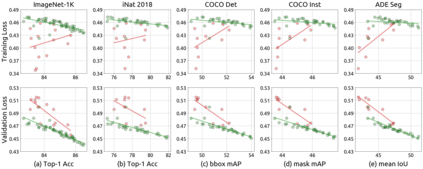
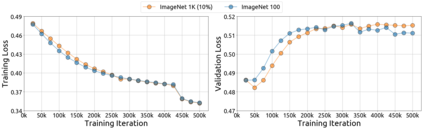
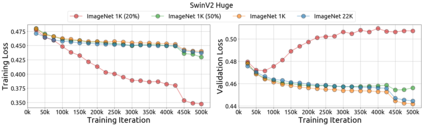
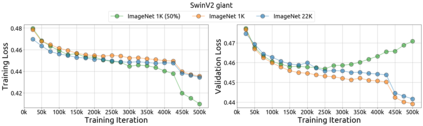
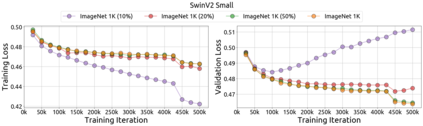
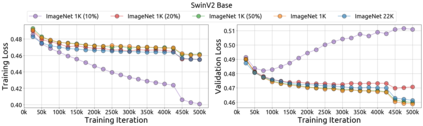
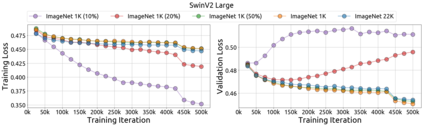
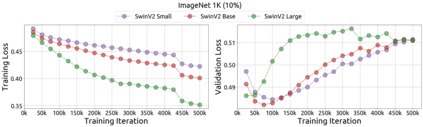
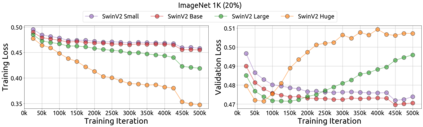
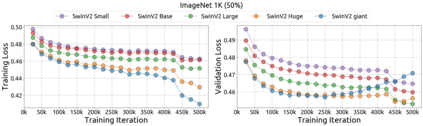
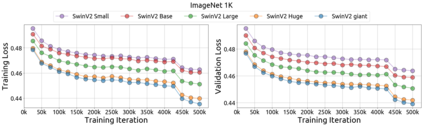
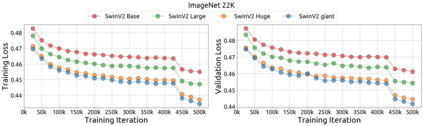
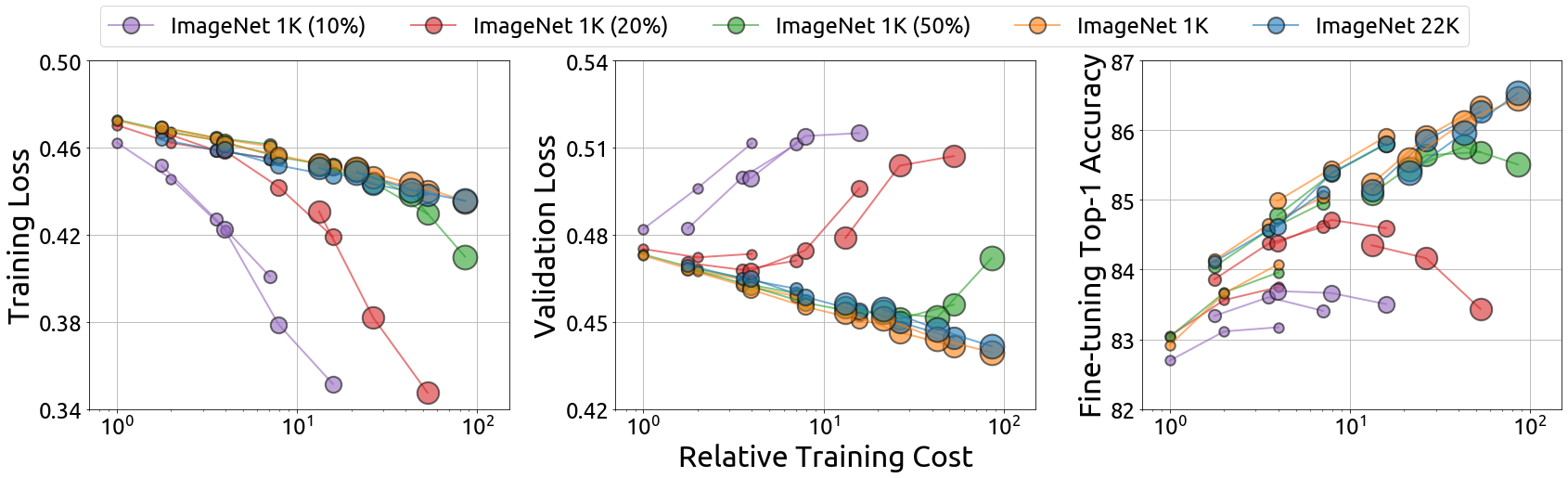
An important goal of self-supervised learning is to enable model pre-training to benefit from almost unlimited data. However, one method that has recently become popular, namely masked image modeling (MIM), is suspected to be unable to benefit from larger data. In this work, we break this misconception through extensive experiments, with data scales ranging from 10\% of ImageNet-1K to full ImageNet-22K, model sizes ranging from 49 million to 1 billion, and training lengths ranging from 125K iterations to 500K iterations. Our study reveals that: (i) Masked image modeling is also demanding on larger data. We observed that very large models got over-fitted with relatively small data; (ii) The length of training matters. Large models trained with masked image modeling can benefit from more data with longer training; (iii) The validation loss in pre-training is a good indicator to measure how well the model performs for fine-tuning on multiple tasks. This observation allows us to pre-evaluate pre-trained models in advance without having to make costly trial-and-error assessments of downstream tasks. We hope that our findings will advance the understanding of masked image modeling in terms of scaling ability.
翻译:自我监督学习的一个重要目标是使示范培训前阶段能够从几乎没有限制的数据中受益。然而,最近流行的一种方法,即蒙面图像建模(MIM),被怀疑无法从更大的数据中受益。在这项工作中,我们通过广泛的实验打破了这种误解,从图像Net-1K的10 ⁇ 到完整的图像网22K的数据规模,模型大小从4 900万到10亿不等,培训长度从125K迭代到500K迭代不等。我们的研究显示:(一) 蒙面图像建模也要求更大的数据。我们发现,非常大的模型过于适合相对较小的数据;(二) 培训时间长。受过蒙面图像建模培训的大型模型可以从更长的培训中得益;(三) 培训前的验证损失是一个良好的指标,用来衡量模型在对多项任务进行微调时的表现有多好。这一观察使我们能够预先评价预先训练的模型,而不必对下游任务进行代价昂贵的试测。我们希望,我们的调查结果将提高模型的印象。