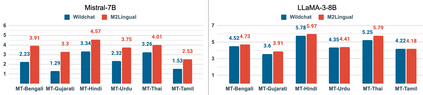
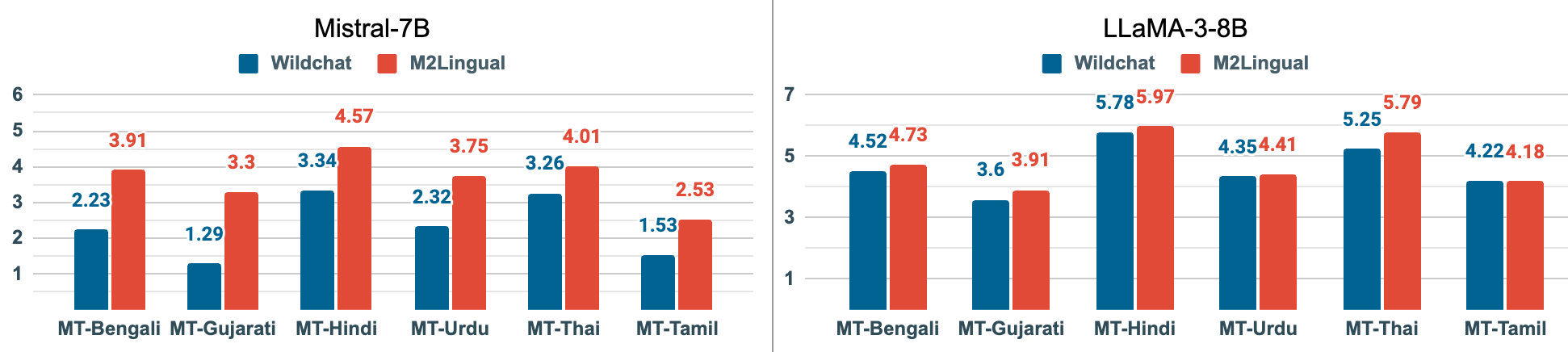
Instruction finetuning (IFT) is critical for aligning Large Language Models (LLMs) to follow instructions. Numerous effective IFT datasets have been proposed in the recent past, but most focus on high resource languages such as English. In this work, we propose a fully synthetic, novel taxonomy (Evol) guided Multilingual, Multi-turn instruction finetuning dataset, called M2Lingual, to better align LLMs on a diverse set of languages and tasks. M2Lingual contains a total of 182K IFT pairs that are built upon diverse seeds, covering 70 languages, 17 NLP tasks and general instruction-response pairs. LLMs finetuned with M2Lingual substantially outperform the majority of existing multilingual IFT datasets. Importantly, LLMs trained with M2Lingual consistently achieve competitive results across a wide variety of evaluation benchmarks compared to existing multilingual IFT datasets. Specifically, LLMs finetuned with M2Lingual achieve strong performance on our translated multilingual, multi-turn evaluation benchmark as well as a wide variety of multilingual tasks. Thus we contribute, and the 2 step Evol taxonomy used for its creation. M2Lingual repository - https://huggingface.co/datasets/ServiceNow-AI/M2Lingual
翻译:暂无翻译