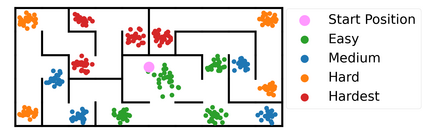
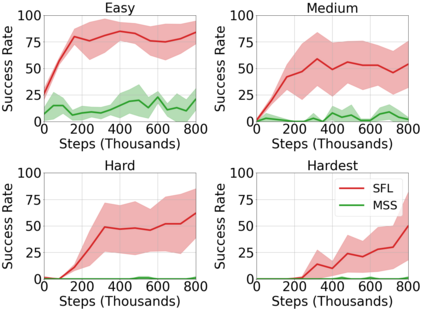
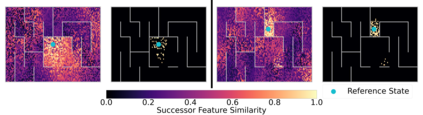
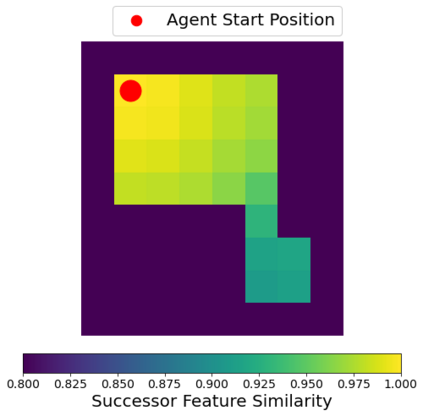
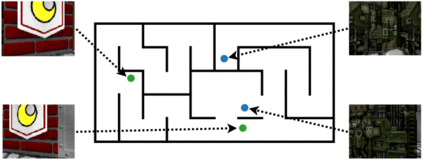
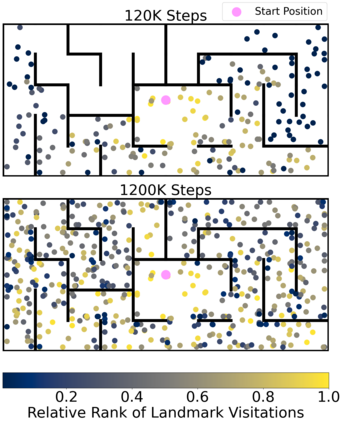
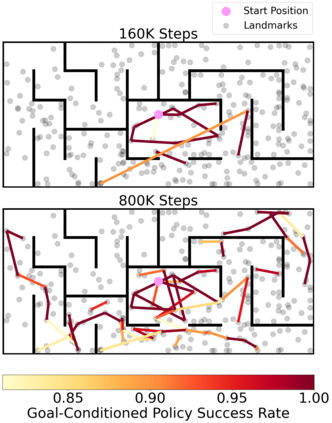
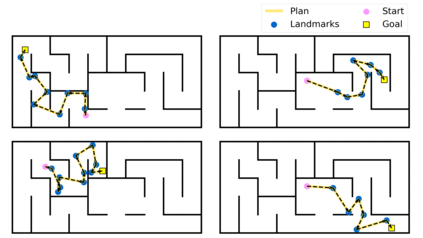
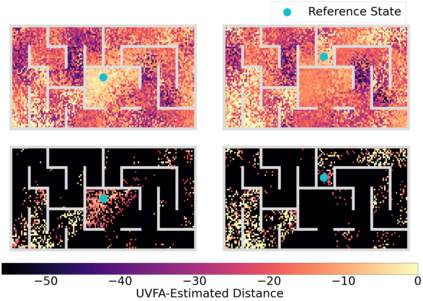
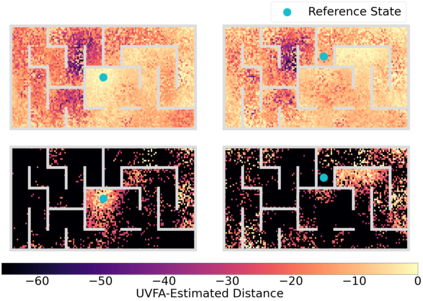
Operating in the real-world often requires agents to learn about a complex environment and apply this understanding to achieve a breadth of goals. This problem, known as goal-conditioned reinforcement learning (GCRL), becomes especially challenging for long-horizon goals. Current methods have tackled this problem by augmenting goal-conditioned policies with graph-based planning algorithms. However, they struggle to scale to large, high-dimensional state spaces and assume access to exploration mechanisms for efficiently collecting training data. In this work, we introduce Successor Feature Landmarks (SFL), a framework for exploring large, high-dimensional environments so as to obtain a policy that is proficient for any goal. SFL leverages the ability of successor features (SF) to capture transition dynamics, using it to drive exploration by estimating state-novelty and to enable high-level planning by abstracting the state-space as a non-parametric landmark-based graph. We further exploit SF to directly compute a goal-conditioned policy for inter-landmark traversal, which we use to execute plans to "frontier" landmarks at the edge of the explored state space. We show in our experiments on MiniGrid and ViZDoom that SFL enables efficient exploration of large, high-dimensional state spaces and outperforms state-of-the-art baselines on long-horizon GCRL tasks.
翻译:在现实世界中运行的代理商往往需要了解复杂的环境,并运用这种理解来达到广泛的目标。这个问题被称为以目标为条件的强化学习(GCRL),对长期远距目标特别具有挑战性。目前的方法已经通过以图表为基础的规划算法来强化以目标为条件的政策来解决这个问题。然而,他们努力将国家空间作为非参数基于地标的图表进行抽取,从而能够进行高级别规划。在这项工作中,我们引入了“成功地标”(SFL),这是探索大型高地标的框架,以便获得一个适合任何目标的政策。SFL利用后续地貌(SF)的能力来捕捉过渡动态,利用它来驱动探索,通过估算州-新星和通过将国家空间抽取为非参数基于地标的图表来进行高级别规划。我们进一步利用SFW,直接为大地标志(SFL)制定一种以目标为条件的政策,我们用来在探索空间的边缘执行“更前沿”的标志,以便获得一种适合任何目标的政策。SFL(SF)利用它来推动探索高空空间的高空空间的“最前沿”,我们在高空空间的MIG-FL(S-FL)的实验中展示。我们展示了在高空空间的高级空间的实验。