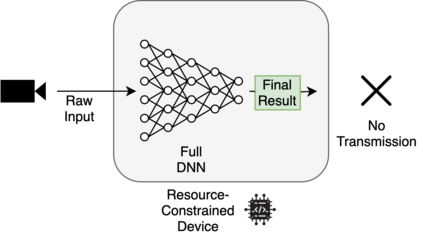
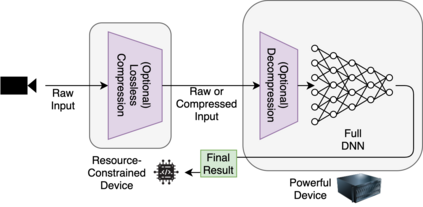
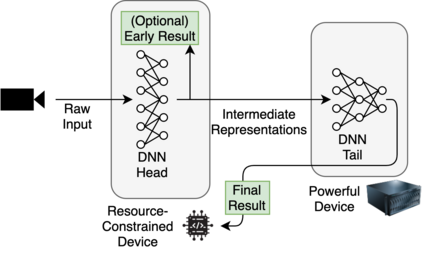
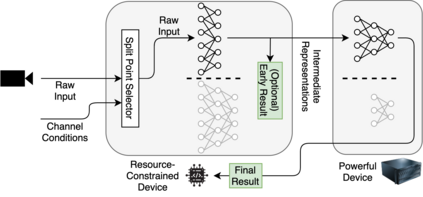
Deploying deep neural networks (DNNs) on IoT and mobile devices is a challenging task due to their limited computational resources. Thus, demanding tasks are often entirely offloaded to edge servers which can accelerate inference, however, it also causes communication cost and evokes privacy concerns. In addition, this approach leaves the computational capacity of end devices unused. Split computing is a paradigm where a DNN is split into two sections; the first section is executed on the end device, and the output is transmitted to the edge server where the final section is executed. Here, we introduce dynamic split computing, where the optimal split location is dynamically selected based on the state of the communication channel. By using natural bottlenecks that already exist in modern DNN architectures, dynamic split computing avoids retraining and hyperparameter optimization, and does not have any negative impact on the final accuracy of DNNs. Through extensive experiments, we show that dynamic split computing achieves faster inference in edge computing environments where the data rate and server load vary over time.
翻译:在 IOT 和 移动设备上部署深神经网络(DNN) 是一项艰巨的任务, 原因是它们的计算资源有限。 因此, 要求性任务往往被完全卸到边缘服务器上, 从而可以加速推论, 但是, 也会引起通信成本和隐私问题。 此外, 这种方法使得终端设备的计算能力无法使用。 分割计算是一种范例, 将 DNN 分成两个部分; 第一部分在终端设备上执行, 产出被传送到执行最后部分的边缘服务器 。 在这里, 我们引入动态分割计算, 最佳分割位置是根据通信频道的状态动态选择的。 通过使用现代 DNN 结构中已经存在的自然瓶颈, 动态分割计算避免了再培训和超参数优化, 并且不会对 DNN 的最终精度产生任何负面影响。 我们通过广泛的实验, 动态分割计算可以在数据率和服务器负荷随时间变化的边缘计算环境中实现更快的推断值 。