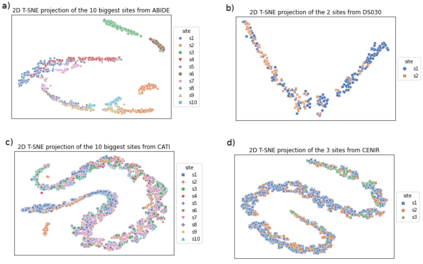
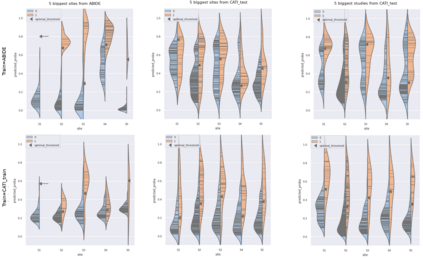
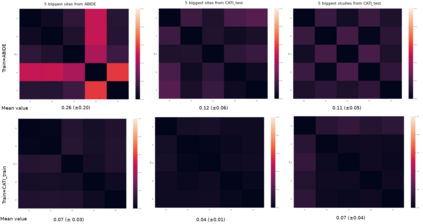
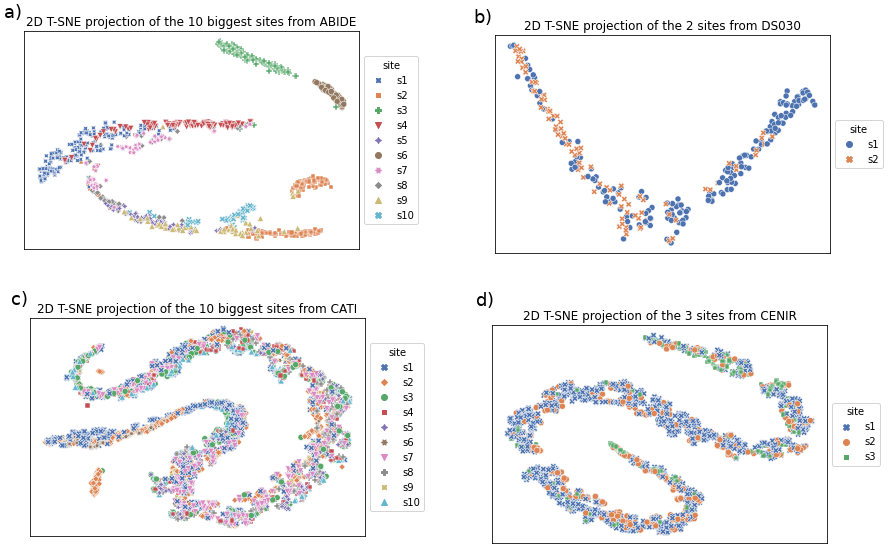
Due to the growing number of MRI data, automated quality control (QC) has become essential, especially for larger scale analysis. Several attempts have been made in order to develop reliable and scalable QC pipelines. However, the generalization of these methods on new data independent of those used for learning is a difficult problem because of the biases inherent in MRI data. This work aimed at evaluating the performances of the MRIQC pipeline on various large-scale datasets (ABIDE, N = 1102 and CATI derived datasets, N = 9037) used for both training and evaluation purposes. We focused our analysis on the MRIQC preprocessing steps and tested the pipeline with and without them. We further analyzed the site-wise and study-wise predicted classification probability distributions of the models without preprocessing trained on ABIDE and CATI data. Our main results were that a model using features extracted from MRIQC without preprocessing yielded the best results when trained and evaluated on large multi-center datasets with a heterogeneous population (an improvement of the ROC-AUC score on unseen data of 0.10 for the model trained on a subset of the CATI dataset). We concluded that a model trained with data from a heterogeneous population, such as the CATI dataset, provides the best scores on unseen data. In spite of the performance improvement, the generalization abilities of the models remain questionable when looking at the site-wise/study-wise probability predictions and the optimal classification threshold derived from them.
翻译:由于磁共振数据不断增多,自动质量控制(QC)变得至关重要,特别是对于更大规模的分析尤其如此。我们曾几次试图开发可靠和可扩缩的QC管道。然而,由于磁共振数据固有的偏差,将这些方法的通用方法用于与学习所用数据无关的新数据是一个困难的问题。这项工作旨在评价磁共振离心管道中各种大型数据集(ABIDE、N=1102和CATI衍生的数据集,N=9037)的性能,用于培训和评估目的。我们集中分析了磁共振离子预处理步骤,测试了输油管道。我们进一步分析了未经对磁共振和CATI数据进行预先处理的模型和预测的分类概率分布。我们的主要结果是,在对大型多子数据集(ABIDE、N=1102和CATI衍生的数据集,N=1102和CATI)进行训练和评价时,取得了最佳结果。我们从ROC-AUC模型的分数,从0.10的奥氏结果模型中测试了输结果。我们所培训的ASMI数据系列数据,因此,我们所培训的轨道数据仍具备了精确的数据。