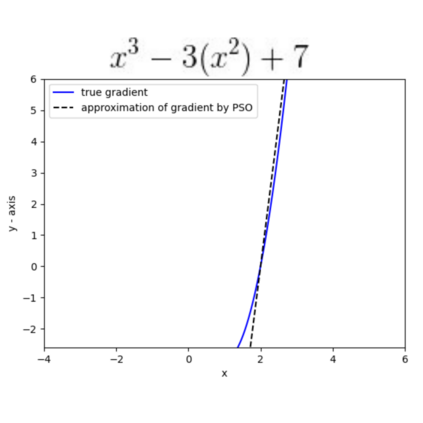
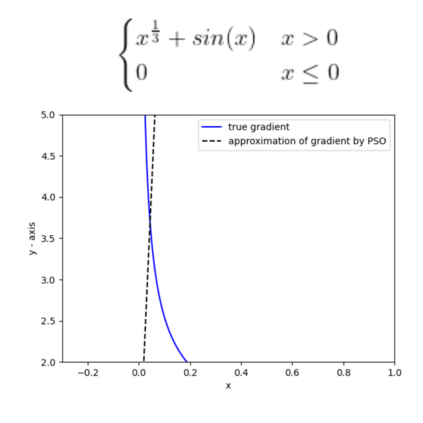
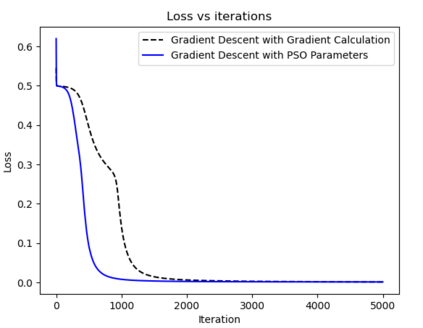
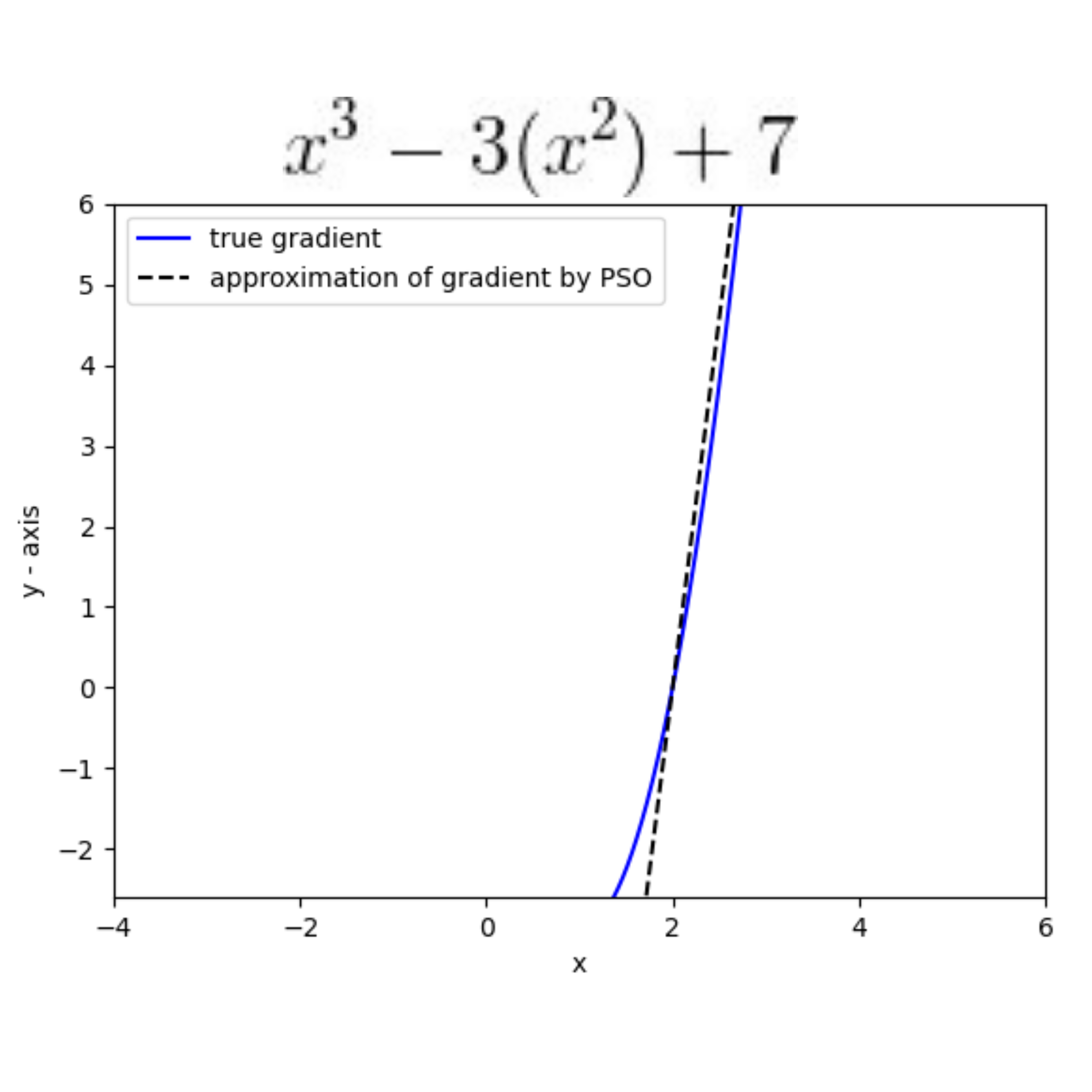
This paper introduces AdaSwarm, a novel gradient-free optimizer which has similar or even better performance than the Adam optimizer adopted in neural networks. In order to support our proposed AdaSwarm, a novel Exponentially weighted Momentum Particle Swarm Optimizer (EMPSO), is proposed. The ability of AdaSwarm to tackle optimization problems is attributed to its capability to perform good gradient approximations. We show that, the gradient of any function, differentiable or not, can be approximated by using the parameters of EMPSO. This is a novel technique to simulate GD which lies at the boundary between numerical methods and swarm intelligence. Mathematical proofs of the gradient approximation produced are also provided. AdaSwarm competes closely with several state-of-the-art (SOTA) optimizers. We also show that AdaSwarm is able to handle a variety of loss functions during backpropagation, including the maximum absolute error (MAE).
翻译:本文介绍AdaSwarm, 这是一种新型的无梯度优化器,其性能与神经网络中采用的亚当优化器相似,甚至更好。为了支持我们提议的AdaSwarm, 提出了一个新的光学加权粒子蒸汽优化器(EMPSO),AdaSwarm 处理优化问题的能力可归因于其执行良好梯度近似的能力。我们表明,使用 EMPSO 的参数可以比较任何功能的梯度,无论是否不同。这是一种模拟GD的新型技术,它位于数字方法与温度智能之间的边界。还提供了所制作的梯度近距离的数学证据。AdaSwarm与数个状态的(SOTA)优化器进行密切竞争。我们还表明,AdaSwarm在回调期间能够处理各种损失功能,包括最大绝对错误(MAE)。