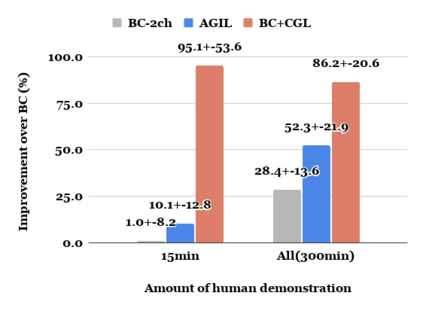
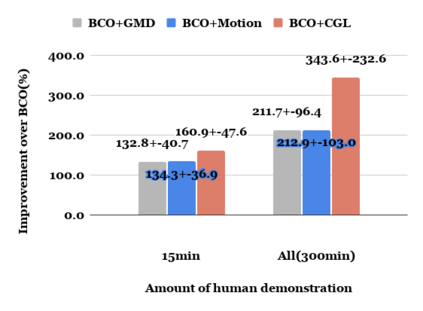
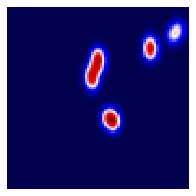
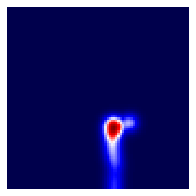
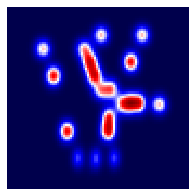
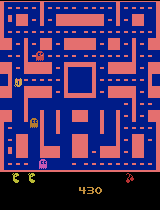
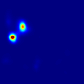
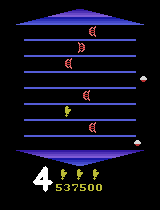
Human gaze is known to be an intention-revealing signal in human demonstrations of tasks. In this work, we use gaze cues from human demonstrators to enhance the performance of agents trained via three popular imitation learning methods -- behavioral cloning (BC), behavioral cloning from observation (BCO), and Trajectory-ranked Reward EXtrapolation (T-REX). Based on similarities between the attention of reinforcement learning agents and human gaze, we propose a novel approach for utilizing gaze data in a computationally efficient manner, as part of an auxiliary loss function, which guides a network to have higher activations in image regions where the human's gaze fixated. This work is a step towards augmenting any existing convolutional imitation learning agent's training with auxiliary gaze data. Our auxiliary coverage-based gaze loss (CGL) guides learning toward a better reward function or policy, without adding any additional learnable parameters and without requiring gaze data at test time. We find that our proposed approach improves the performance by 95% for BC, 343% for BCO, and 390% for T-REX, averaged over 20 different Atari games. We also find that compared to a prior state-of-the-art imitation learning method assisted by human gaze (AGIL), our method achieves better performance, and is more efficient in terms of learning with fewer demonstrations. We further interpret trained CGL agents with a saliency map visualization method to explain their performance. At last, we show that CGL can help alleviate a well-known causal confusion problem in imitation learning.
翻译:人类的目视是人类任务演示中的一种意向反映信号。 在这项工作中,我们使用人类示威者的凝视提示来提高通过三种流行模仿学习方法 -- -- 行为性克隆(BC)、观察中的行为性克隆(BCO)和轨迹分级的 " Reward Extraction " (T-REX) -- -- 培训的代理人的性能。根据强化学习代理人和人眼的注意之间的相似性,我们建议采用一种新的方法,以计算高效的方式利用凝视数据,作为辅助损失功能的一部分,指导网络在人类凝视固定的图像区域进行更高程度的启动。这项工作是加强任何现有的共振动模仿学习代理人用辅助凝视数据进行的培训的一个步骤。我们基于辅助性的凝视损失(CGL)指导学习更好的奖励功能或政策,不增加任何可学习的参数,也不需要在测试时使用凝视数据。我们提出的方法可以使BC、BCO和TRIX的3.90 %的图象区域区域进行更高的激活活动。我们发现,在经过训练的C-C级的视觉演化方法中可以更准确地解释一个更好的表现方法。