
Co-part segmentation is an important problem in computer vision for its rich applications. We propose an unsupervised learning approach for co-part segmentation from images. For the training stage, we leverage motion information embedded in videos and explicitly extract latent representations to segment meaningful object parts. More importantly, we introduce a dual procedure of part-assembly to form a closed loop with part-segmentation, enabling an effective self-supervision. We demonstrate the effectiveness of our approach with a host of extensive experiments, ranging from human bodies, hands, quadruped, and robot arms. We show that our approach can achieve meaningful and compact part segmentation, outperforming state-of-the-art approaches on diverse benchmarks.
翻译:共同分割是计算机对其丰富应用的愿景的一个重要问题。 我们提出一种不受监督的从图像中共同分割的学习方法。 在培训阶段,我们利用视频中嵌入的移动信息,并明确提取潜在表达方式来分割有意义的物体部分。 更重要的是,我们引入了半集合的双重程序,以形成一个包含部分分割的闭路循环,从而能够进行有效的自我监督。我们通过从人体、手、四肢和机器人武器等广泛的实验,展示了我们的方法的有效性。我们展示了我们的方法能够实现有意义和紧凑的分割,在各种基准上优于最先进的方法。









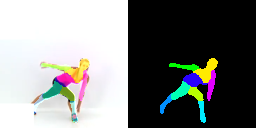
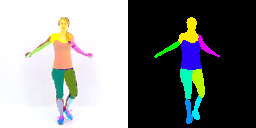


























































相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem


