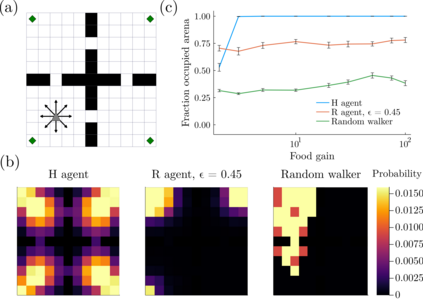
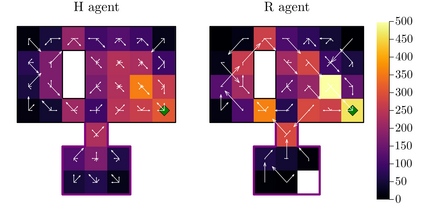
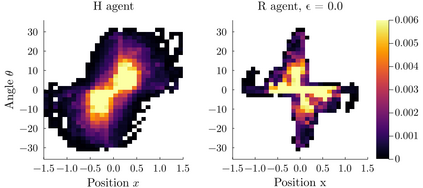
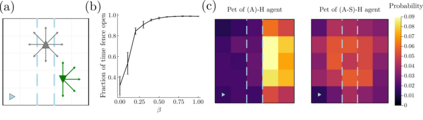
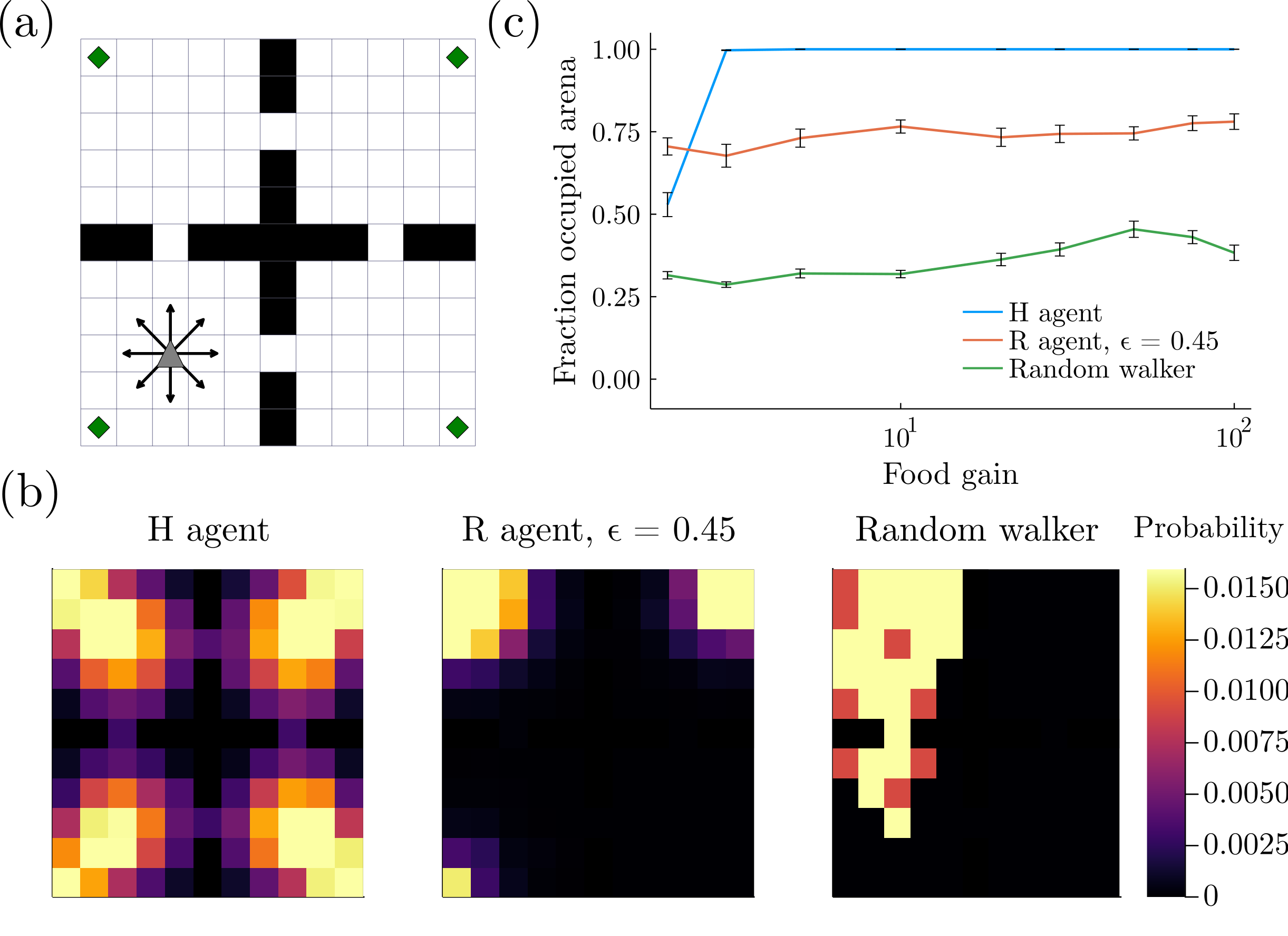
Intrinsic motivation generates behaviors that do not necessarily lead to immediate reward, but help exploration and learning. Here we show that agents having the sole goal of maximizing occupancy of future actions and states, that is, moving and exploring on the long term, are capable of complex behavior without any reference to external rewards. We find that action-state path entropy is the only measure consistent with additivity and other intuitive properties of expected future action-state path occupancy. We provide analytical expressions that relate the optimal policy with the optimal state-value function, from where we prove uniqueness of the solution of the associated Bellman equation and convergence of our algorithm to the optimal state-value function. Using discrete and continuous state tasks, we show that `dancing', hide-and-seek and a basic form of altruistic behavior naturally result from entropy seeking without external rewards. Intrinsically motivated agents can objectively determine what states constitute rewards, exploiting them to ultimately maximize action-state path entropy.
翻译:自然动机产生的行为不一定导致立即奖励,而是有助于探索和学习。 我们在这里展示了那些唯一目标是最大限度地占用未来行动的代理人, 并且从长远来看, 移动和探索能够产生复杂的行为, 而不提外部奖励。 我们发现, 行动状态路径的催化是符合预期未来行动状态路径占用的附加性和其他直觉特性的唯一衡量标准。 我们提供的分析表达方式将最佳政策与最佳国家价值功能联系起来, 从我们证明相关的贝尔曼方程式解决方案的独特性以及我们算法与最佳国家价值函数的趋同性。 我们使用离散和持续的国家任务, 显示“ 跳舞 ” 、 隐藏和寻找, 以及一种基本的利他主义行为形式, 其自然结果就是在没有外部奖励的情况下寻求。 具有内在动机的代理人可以客观地确定什么是奖赏, 利用它们最终将动作状态路径最大化。