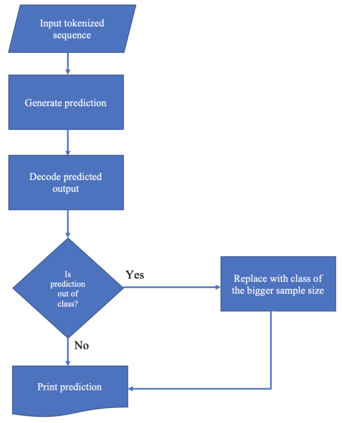
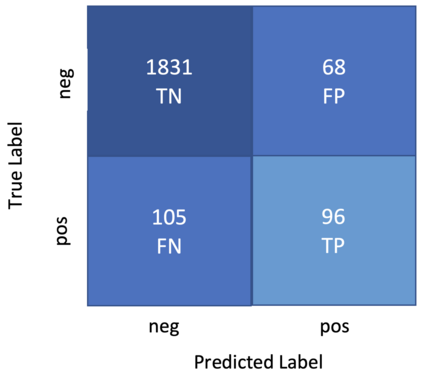
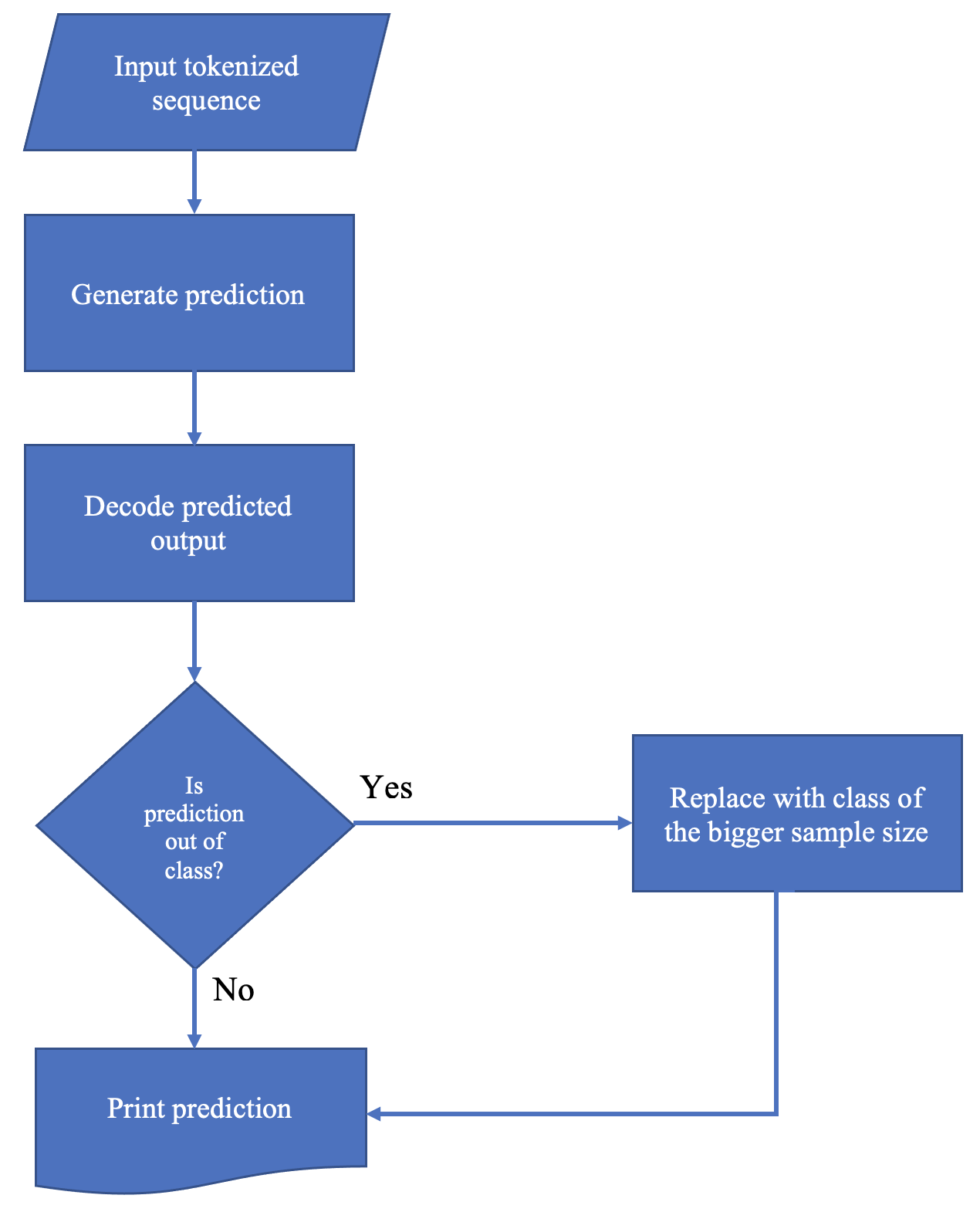
This paper describes the system used by the Machine Learning Group of LTU in subtask 1 of the SemEval-2022 Task 4: Patronizing and Condescending Language (PCL) Detection. Our system consists of finetuning a pretrained Text-to-Text-Transfer Transformer (T5) and innovatively reducing its out-of-class predictions. The main contributions of this paper are 1) the description of the implementation details of the T5 model we used, 2) analysis of the successes & struggles of the model in this task, and 3) ablation studies beyond the official submission to ascertain the relative importance of data split. Our model achieves an F1 score of 0.5452 on the official test set.
翻译:本文件介绍了LTU机械学习小组在SemEval-2022任务4:辅助和征服语言(PCL)探测的子任务1中使用的系统,我们的系统包括微调一个经过预先培训的文本到文本转换变异器(T5),并创新地减少其课外预测。本文的主要贡献是:(1) 说明我们使用的T5模型的实施细节,(2) 分析该模型在这项任务中的成功和挣扎情况,(3) 将正式提交后进行对比研究,以确定数据分离的相对重要性。我们的模型在正式测试集上取得了0.5452的F1分。