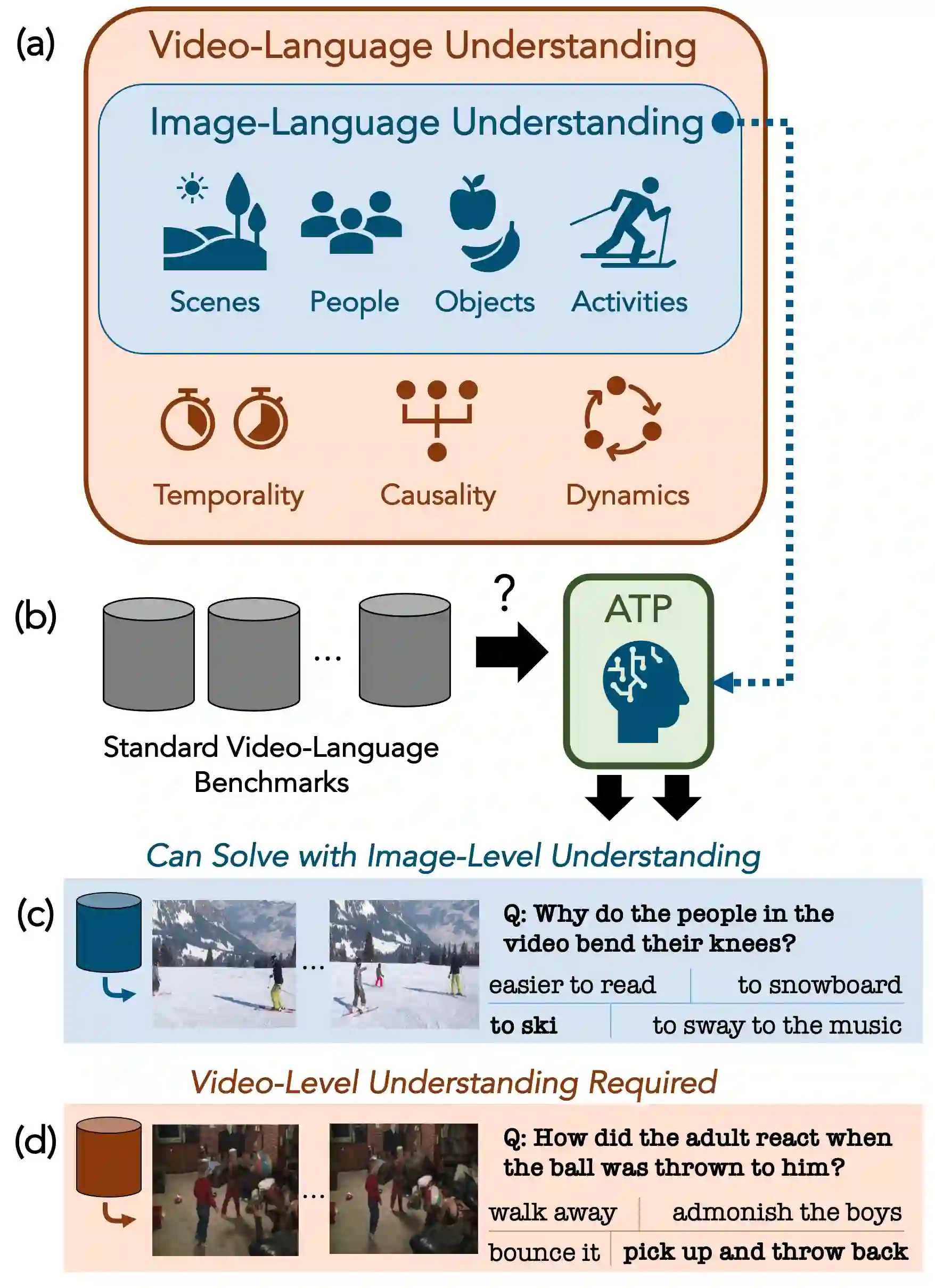
What makes a video task uniquely suited for videos, beyond what can be understood from a single image? Building on recent progress in self-supervised image-language models, we revisit this question in the context of video and language tasks. We propose the atemporal probe (ATP), a new model for video-language analysis which provides a stronger bound on the baseline accuracy of multimodal models constrained by image-level understanding. By applying this model to standard discriminative video and language tasks, such as video question answering and text-to-video retrieval, we characterize the limitations and potential of current video-language benchmarks. We find that understanding of event temporality is often not necessary to achieve strong or state-of-the-art performance, even compared with recent large-scale video-language models and in contexts intended to benchmark deeper video-level understanding. We also demonstrate how ATP can improve both video-language dataset and model design. We describe a technique for leveraging ATP to better disentangle dataset subsets with a higher concentration of temporally challenging data, improving benchmarking efficacy for causal and temporal understanding. Further, we show that effectively integrating ATP into full video-level temporal models can improve efficiency and state-of-the-art accuracy.
翻译:怎样才能使视频任务特别适合视频,超越从单一图像中可以理解的视频任务?我们根据在自我监督的图像语言模型方面最近取得的进展,在视频和语言任务的背景下重新审视这一问题。我们提议了时空探测(ATP),这是一个新的视频分析新模式,它为受图像水平理解制约的多式联运模型的基线准确性提供了更强有力的约束。我们将这一模式应用于标准的歧视性视频和语言任务,例如视频问答和文本到视频的检索,从而确定了当前视频语言基准的局限性和潜力。我们发现,即使与最近的大型视频语言模型相比,在为更深层次的视频理解制定基准的背景下,对事件时间性的理解也往往没有必要。我们还演示了ATP如何改进视频语言数据集和模型设计。我们描述了一种利用ATP更好地解析数据子集,使时间挑战性数据更加集中,提高因果关系和时间理解度。此外,我们展示了将ATP有效地纳入全视频水平的准确度能够提高效率和状态。