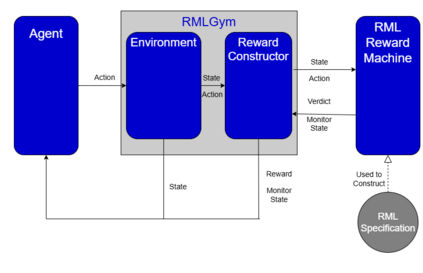
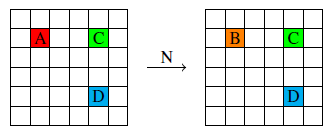
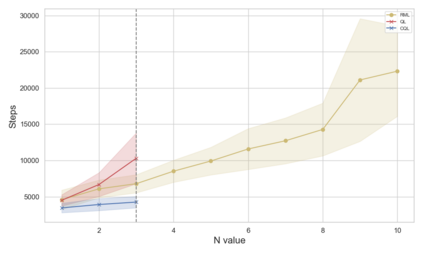
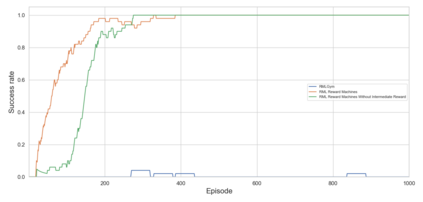
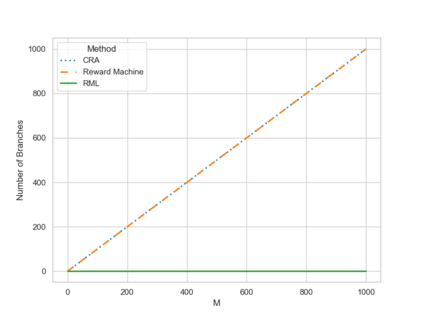
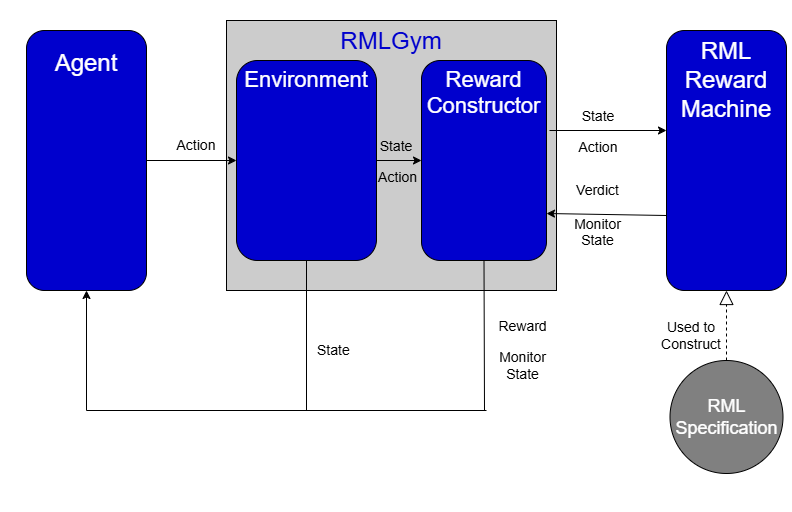
A key challenge in reinforcement learning (RL) is reward (mis)specification, whereby imprecisely defined reward functions can result in unintended, possibly harmful, behaviours. Indeed, reward functions in RL are typically treated as black-box mappings from state-action pairs to scalar values. While effective in many settings, this approach provides no information about why rewards are given, which can hinder learning and interpretability. Reward Machines address this issue by representing reward functions as finite state automata, enabling the specification of structured, non-Markovian reward functions. However, their expressivity is typically bounded by regular languages, leaving them unable to capture more complex behaviours such as counting or parametrised conditions. In this work, we build on the Runtime Monitoring Language (RML) to develop a novel class of language-based Reward Machines. By leveraging the built-in memory of RML, our approach can specify reward functions for non-regular, non-Markovian tasks. We demonstrate the expressiveness of our approach through experiments, highlighting additional advantages in flexible event-handling and task specification over existing Reward Machine-based methods.
翻译:暂无翻译