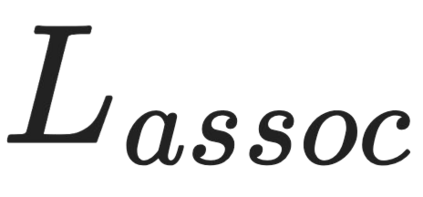We propose a new task and model for dense video object captioning -- detecting, tracking, and captioning trajectories of all objects in a video. This task unifies spatial and temporal understanding of the video, and requires fine-grained language description. Our model for dense video object captioning is trained end-to-end and consists of different modules for spatial localization, tracking, and captioning. As such, we can train our model with a mixture of disjoint tasks, and leverage diverse, large-scale datasets which supervise different parts of our model. This results in noteworthy zero-shot performance. Moreover, by finetuning a model from this initialization, we can further improve our performance, surpassing strong image-based baselines by a significant margin. Although we are not aware of other work performing this task, we are able to repurpose existing video grounding datasets for our task, namely VidSTG and VLN. We show our task is more general than grounding, and models trained on our task can directly be applied to grounding by finding the bounding box with the maximum likelihood of generating the query sentence. Our model outperforms dedicated, state-of-the-art models for spatial grounding on both VidSTG and VLN.
翻译:暂无翻译