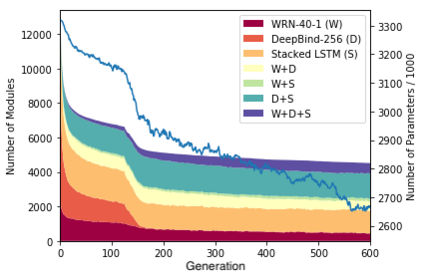
As deep learning applications continue to become more diverse, an interesting question arises: Can general problem solving arise from jointly learning several such diverse tasks? To approach this question, deep multi-task learning is extended in this paper to the setting where there is no obvious overlap between task architectures. The idea is that any set of (architecture,task) pairs can be decomposed into a set of potentially related subproblems, whose sharing is optimized by an efficient stochastic algorithm. The approach is first validated in a classic synthetic multi-task learning benchmark, and then applied to sharing across disparate architectures for vision, NLP, and genomics tasks. It discovers regularities across these domains, encodes them into sharable modules, and combines these modules systematically to improve performance in the individual tasks. The results confirm that sharing learned functionality across diverse domains and architectures is indeed beneficial, thus establishing a key ingredient for general problem solving in the future.
翻译:随着深层次学习应用的日益多样化,产生了一个有趣的问题:共同学习多种不同任务,能否解决一般性问题?为了解决这一问题,本文件将深度多任务学习扩大到任务结构之间没有明显重叠的地方。想法是,任何一组(建筑、塔萨克)对子(建筑、塔萨克)配对都可以分解成一套可能相关的子问题,通过高效的随机算法优化共享。这种方法首先在经典的合成多任务学习基准中验证,然后用于共享不同结构的视觉、NLP和基因组任务。它发现这些领域的常规性,将其编码为可辨别模块,并系统地将这些模块组合起来,以改进单个任务的业绩。结果证实,共享不同领域和结构的学习功能确实是有益的,从而为今后解决一般性问题奠定了关键要素。