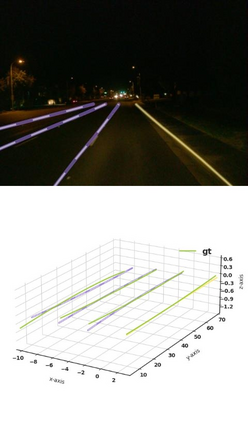
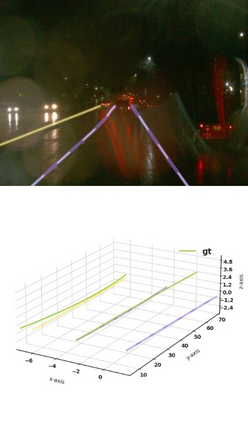
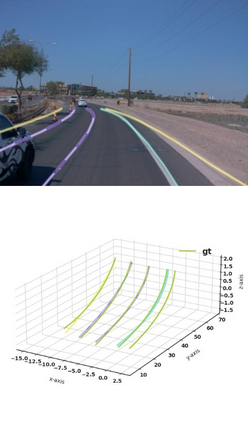
Estimating accurate lane lines in 3D space remains challenging due to their sparse and slim nature. In this work, we propose the M^2-3DLaneNet, a Multi-Modal framework for effective 3D lane detection. Aiming at integrating complementary information from multi-sensors, M^2-3DLaneNet first extracts multi-modal features with modal-specific backbones, then fuses them in a unified Bird's-Eye View (BEV) space. Specifically, our method consists of two core components. 1) To achieve accurate 2D-3D mapping, we propose the top-down BEV generation. Within it, a Line-Restricted Deform-Attention (LRDA) module is utilized to effectively enhance image features in a top-down manner, fully capturing the slenderness features of lanes. After that, it casts the 2D pyramidal features into 3D space using depth-aware lifting and generates BEV features through pillarization. 2) We further propose the bottom-up BEV fusion, which aggregates multi-modal features through multi-scale cascaded attention, integrating complementary information from camera and LiDAR sensors. Sufficient experiments demonstrate the effectiveness of M^2-3DLaneNet, which outperforms previous state-of-the-art methods by a large margin, i.e., 12.1% F1-score improvement on OpenLane dataset.
翻译:估计3D空间的准确航道仍因其稀少和细小的性质而具有挑战性。 在这项工作中,我们建议使用M%2-3DLaneNet,这是一个用于有效探测3D航道的多模式框架。M%2-3DLaneNet首先从多传感器中提取多模式特征,然后用一个统一的鸟类Eye视图(BEV)空间将其结合为3D空间。具体地说,我们的方法由两个核心组成部分组成。(1) 为了实现准确的 2D-3D 映射,我们建议采用自上而下的BEV 新一代。在其中,使用一个自上而下的限制变形-保护(LDA)模块,以自上而下的方式有效地增强图像特征,充分捕捉各航道的细度特征。之后,将2D金字塔特征投放到3D空间中,利用深度的提升和生成BEV的特性。(2) 我们进一步建议采用自下而上方的BEV聚合,通过多尺度的升-D级级级级升级将多功能聚合成多式的多模式,将前F-L级图像传感器的合成数据整合。