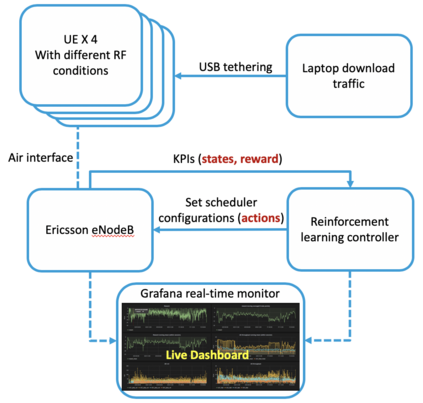
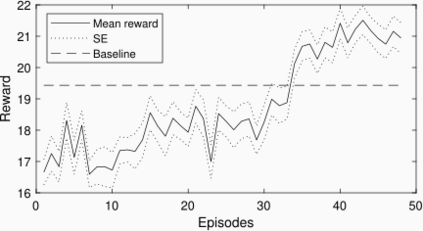
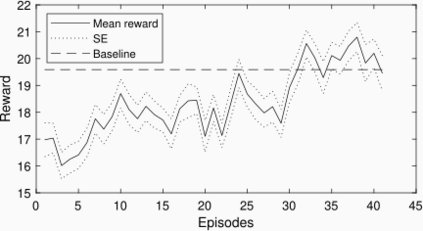
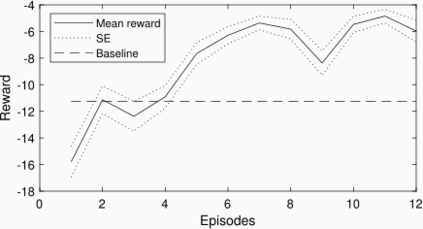
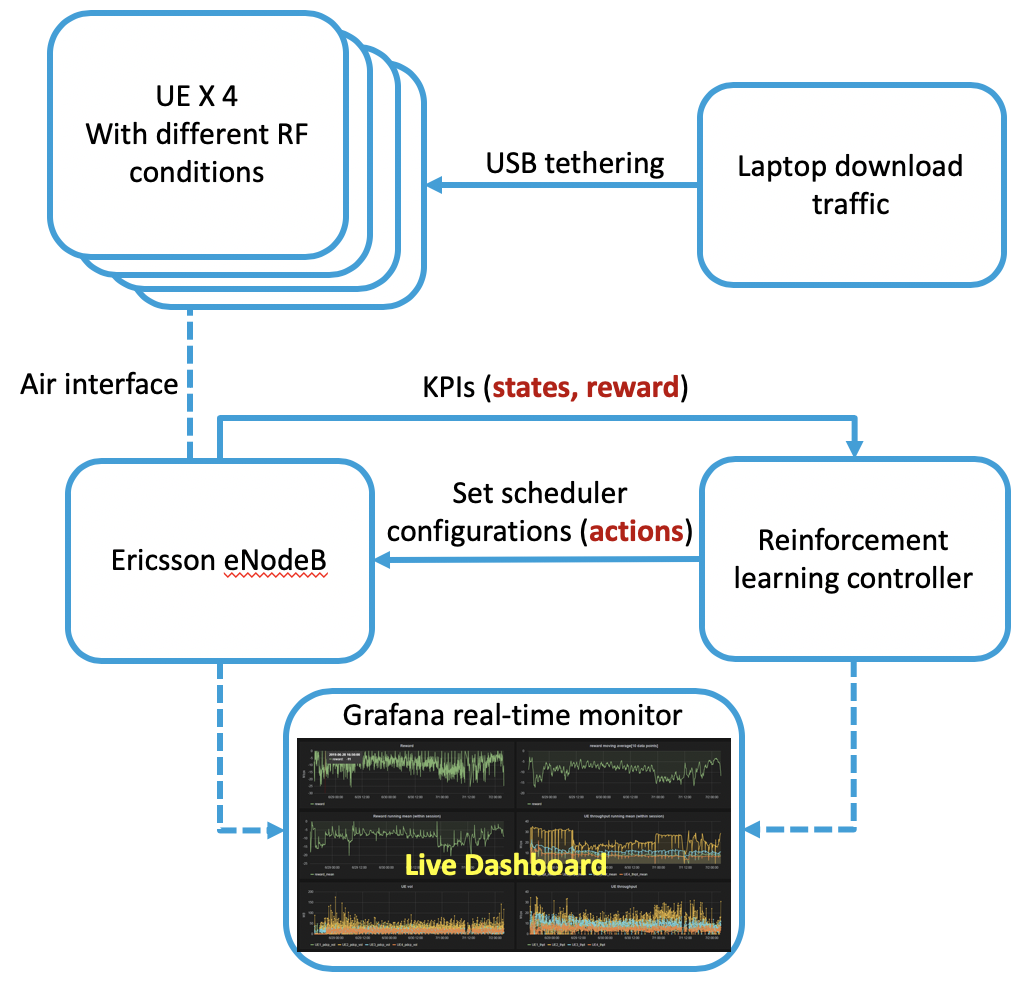
Due to the high variability of the traffic in the radio access network (RAN), fixed network configurations are not flexible enough to achieve optimal performance. Our vendors provide several settings of the eNodeB to optimize the RAN performance, such as media access control scheduler, loading balance, etc. But the detailed mechanisms of the eNodeB configurations are usually very complicated and not disclosed, not to mention the large key performance indicators (KPIs) space needed to be considered. These make constructing a simulator, offline tuning, or rule-based solutions difficult. We aim to build an intelligent controller without strong assumption or domain knowledge about the RAN and can run 24/7 without supervision. To achieve this goal, we first build a closed-loop control testbed RAN in a lab environment with one eNodeB provided by one of the largest wireless vendors and four smartphones. Next, we build a double Q network agent trained with the live feedback of the key performance indicators from the RAN. Our work proved the effectiveness of applying deep reinforcement learning to improve network performance in a real RAN network environment.
翻译:由于无线电接入网络(RAN)的交通量变化很大,固定网络配置不够灵活,无法达到最佳性能。我们的供应商提供了一些eNodeB的设置,以优化REAN性能,例如媒体访问控制调度器、装载平衡等。但是eNodeB配置的详细机制通常非常复杂,没有披露,更不用说需要考虑大型关键性能指标(KPIs)空间。这使得建造模拟器、离线调试或基于规则的解决方案十分困难。我们的目标是在没有关于RAN的强有力假设或域域知识的情况下建立一个智能控制器,并且可以不受监督地24/7运行。为了实现这一目标,我们首先在实验室环境中建立一个闭路控制测试式RAN,由最大的无线供应商之一和四个智能手机提供一种eNodeB。接下来,我们建立一个经过培训的双Q网络代理,对来自RAN的关键性能指标进行实时反馈。我们的工作证明,应用深度强化学习提高网络在真实的RAN网络环境中的性能是有效的。