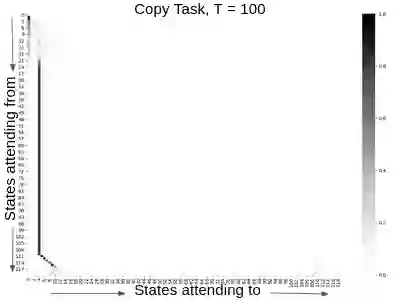
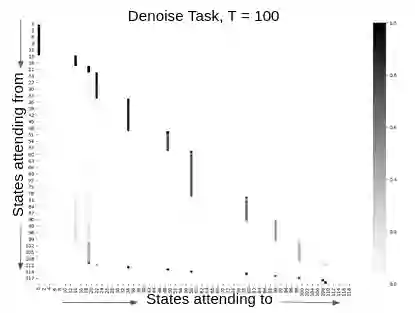
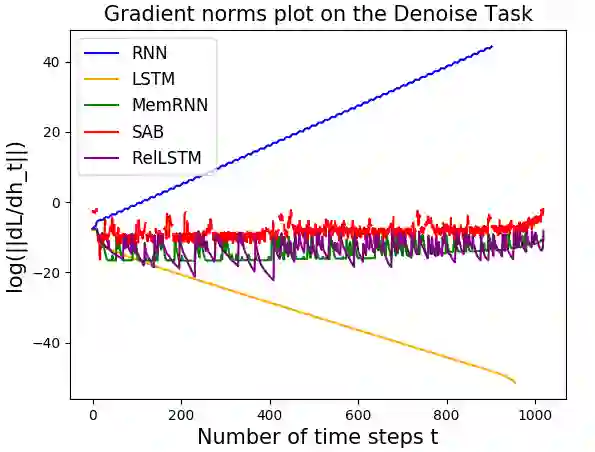
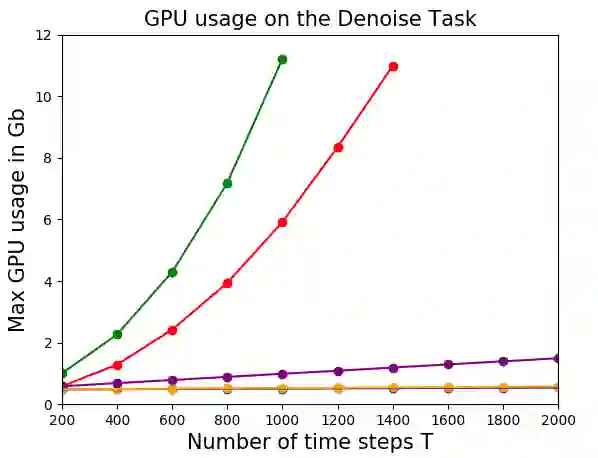
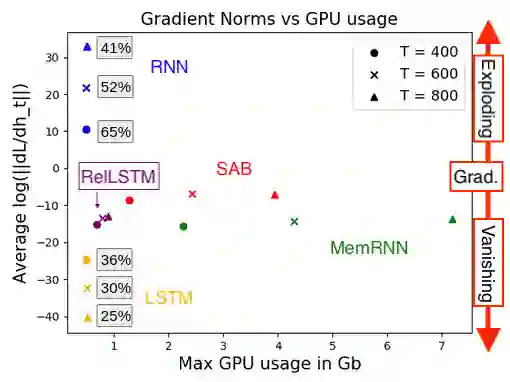
Attention and self-attention mechanisms, are now central to state-of-the-art deep learning on sequential tasks. However, most recent progress hinges on heuristic approaches with limited understanding of attention's role in model optimization and computation, and rely on considerable memory and computational resources that scale poorly. In this work, we present a formal analysis of how self-attention affects gradient propagation in recurrent networks, and prove that it mitigates the problem of vanishing gradients when trying to capture long-term dependencies by establishing concrete bounds for gradient norms. Building on these results, we propose a relevancy screening mechanism, inspired by the cognitive process of memory consolidation, that allows for a scalable use of sparse self-attention with recurrence. While providing guarantees to avoid vanishing gradients, we use simple numerical experiments to demonstrate the tradeoffs in performance and computational resources by efficiently balancing attention and recurrence. Based on our results, we propose a concrete direction of research to improve scalability of attentive networks.
翻译:关注和自我关注机制现在对于在相继任务上进行最先进的深入学习至关重要。然而,最近的进展取决于对关注在模式优化和计算中的作用认识有限、依赖大量记忆和计算资源,而且依赖规模不高的庞大记忆和计算资源。在这项工作中,我们正式分析了自我关注如何影响经常性网络中的梯度传播,并证明在试图通过为梯度规范确定具体界限来捕捉长期依赖性时,可以减轻梯度消失的问题。在这些结果的基础上,我们提议了一个具有相关性的筛选机制,在记忆整合认知过程的启发下,允许以可伸缩的方式利用稀少的自我意识,并重现。我们在提供避免梯度消失的保证的同时,使用简单的数字实验,通过有效平衡关注和重现,来展示在业绩和计算资源上的权衡。我们根据我们的结果,提出具体的研究方向,以提高关注网络的可扩展性。