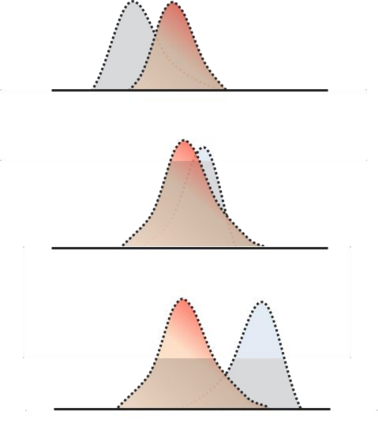
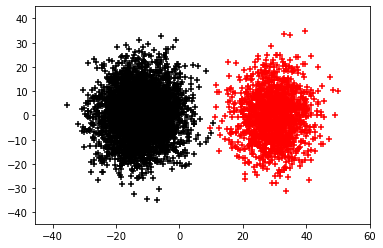
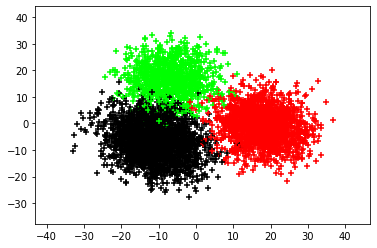
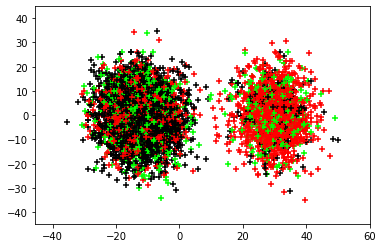
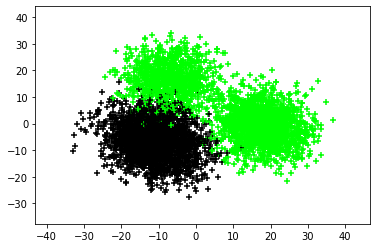
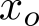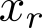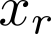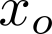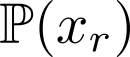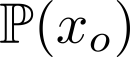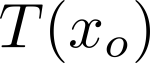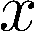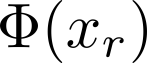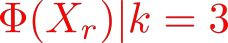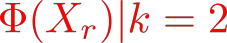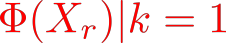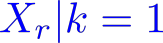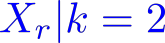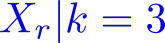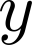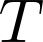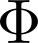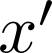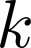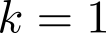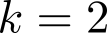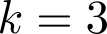Organ transplantation is often the last resort for treating end-stage illness, but the probability of a successful transplantation depends greatly on compatibility between donors and recipients. Current medical practice relies on coarse rules for donor-recipient matching, but is short of domain knowledge regarding the complex factors underlying organ compatibility. In this paper, we formulate the problem of learning data-driven rules for organ matching using observational data for organ allocations and transplant outcomes. This problem departs from the standard supervised learning setup in that it involves matching the two feature spaces (i.e., donors and recipients), and requires estimating transplant outcomes under counterfactual matches not observed in the data. To address these problems, we propose a model based on representation learning to predict donor-recipient compatibility; our model learns representations that cluster donor features, and applies donor-invariant transformations to recipient features to predict outcomes for a given donor-recipient feature instance. Experiments on semi-synthetic and real-world datasets show that our model outperforms state-of-art allocation methods and policies executed by human experts.
翻译:器官移植往往是治疗最终阶段疾病的最后手段,但成功的移植概率在很大程度上取决于捐赠者和接受者之间的兼容性。目前的医疗实践依靠粗糙的规则来进行捐赠者-接受者匹配,但缺乏关于器官兼容性复杂因素的领域知识。在本文件中,我们提出了利用器官分配和移植结果方面的观察数据数据匹配器官的数据驱动规则的学习问题。这个问题不同于标准监督的学习设置,因为它涉及匹配两个特征空间(即捐赠者和接受者),并要求在数据中未观察到的反事实匹配下估计移植结果。为了解决这些问题,我们提出了一个基于代表性学习的模式,以预测捐赠者-接受者兼容性;我们的模式学习了分组捐赠者特征的表述,并将捐赠者-反对变化的转变应用于接受者特征,以预测特定捐赠者-接受者特征实例的结果。半合成和真实世界数据集实验显示,我们的模型超出了人类专家执行的状态分配方法和政策。