Representation Learning on Network 网络表示学习
“全球人工智能”拥有十多万AI产业用户,10000多名AI技术专家。主要来自:北大,清华,中科院,麻省理工,卡内基梅隆,斯坦福,哈佛,牛津,剑桥...以及谷歌,腾讯,百度,脸谱,微软,阿里,海康威视,英伟达......等全球名校和名企。
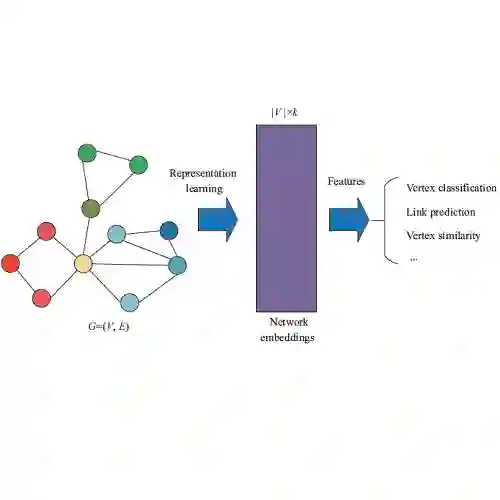
摘要: 网络表示学习(Representation Learning on Network),一般说的就是向量化(Embedding)技术,简单来说,就是将网络中的结构(节点、边或者子图),通过一系列过程,变成一个多维向量,通过这样一层转化,能够将复杂的网络信息变成结构化的多维特征,从而利用机器学习方法实现更方便的算法应用。
Note: 以下是根据综述 [1][2] 梳理的笔记,由于是初探,语言和理论必然有不严谨之处,欢迎指正。
网络表示学习(Representation Learning on Network),一般说的就是向量化(Embedding)技术,简单来说,就是将网络中的结构(节点、边或者子图),通过一系列过程,变成一个多维向量,通过这样一层转化,能够将复杂的网络信息变成结构化的多维特征,从而利用机器学习方法实现更方便的算法应用。
Embedding Nodes
在这些方法中,受研究和应用关注最多的就是节点向量化(Node Embedding),即对于一个图 G=(V,E),学习一种映射:
f:vi→zi∈Rd
其中 zi 是一个输出的多维向量,并且满足d≪|V|。用于评估这个学习效果的标准,就是看向量化后重新复原网络结构的能力。
在[1]中,作者提到节点向量化有3大挑战:
学习属性的选择:不同的向量化表示方法,都是对网络信息的一种摘要。有时我们会倾向于保存网络中节点的近邻关系,有时倾向学习节点在网络中的角色(比如中心节点)。不同的应用对“学习属性”的选择有不同的要求,故而引发了各类算法的爆发。
规模化:现实应用中有很多网络包含了大量的节点和边,高效的向量化方法,能够在短时间内处理超大规模的网络,才比较有实际应用的可能性。
向量维度:如何确定合适的向量表示维度,是一个很难的问题,并且也是和具体场景相关的。事实上,越高的维度可能带来越好的效果,但是会极大降低应用性能。平衡性能和效果,在不同的应用中需要因地制宜。
1. Encoder-decoder View
论文[2] 通过调研今年业界比较流行的向量化方法,提出了一套通用的流程和模型框架。
大部分向量化算法,是属于非监督学习,没有针对特定的图计算任务(比如链路预测或者聚类)进行优化,而是针对图信息的保存情况进行优化学习,其评价标准,就是看其向量化后的数据对原始网络的恢复能力。整个学习过程被抽象为下图所示的框架图,它包括两个过程:
Encoder:负责把每个节点映射到一个低维向量中
Decoder:负责从向量化的信息中重新构建网络结构和节点属性

对于上述框架,它包含4个概念:
节点关系函数 sG:V×V→R+ 衡量两个节点之间的距离
Encode 函数 ENC:V→Rd 将节点映射到 d 维向量
Decode 函数 DEC:Rd×Rd→R+ 将向量化信息重新恢复成节点关系
损失函数 l 用于度量模型刻画能力,比如 DEC(zi,zj) 与 sG(vi,vj)的偏差情况。
对于 Encoder-decoder 框架下现有的 state-of-the-art 模型,[2]的作者提出了几个弱点:
向量化后的节点之间没有参数共享,完全是一种记忆化的模型存储和查询方式(Look-up),这对存储和计算都构成了不小的挑战。由于节点之间没有参数共享,也就大大损失了泛化能力。
目前大部分向量化方法,仅利用网络结构信息,并没有利用网络节点本身的属性(比如文本、图像和统计特征),使得结果向量对网络信息的存储很有限。
大部分模型是对静态网络结构的直推学习,并没有考虑网络时间演化过程中新节点的生成和旧节点的湮灭,而网络的动态特性对理解其性质也至关重要。这个弱点甚至会影响向量化在动态网络上的效果。比如在互联网场景中,每天都有新的结构产生和消除,今天生成的向量化表示,两天后的可用性是否会大打折扣?这是一个值得深思的问题。
2. Encoding Methods
本模块主要介绍3种常见的网络表示学习类别。
2.1 Factorization based
矩阵分解是传统的节点向量化方法,其思想就是对网络的邻接矩阵进行降维,给每个节点生成一个低维表示。
Laplacian Eigenmaps
Laplacian Eigenmaps 的目标是将相似性高的两个节点,映射到低维空间后依然保持距离相近,其损失函数定义为:
L(Z)=12(zi−zj)2Wij=ZTLZ
其中 L 是图 G 的 Laplacian 矩阵,L=D−A,其中 D 是度矩阵,A 是邻接矩阵。
GF
根据[1]的调研,GF(Graph Factorization) 是第一个在 O(|E|) 的时间复杂度上完成向量化的算法。其损失函数定义为:
L(Z,λ)=12∑(i,j)∈E(Wij−<Zi,Zj>)2+λ2∑iZi2
其中 λ 是正则化参数。跟上面的 Laplacian Eigenmaps 相比,GF 算法是将两个向量重构后的边权作为衡量方法,两个向量可能有多种重构方式,比如直接点乘,或者求余弦相似度等等。
HOPE
HOPE(High-Order Proximity preserved Embedding) 模型相比 GF,通过引入 ||S−ZsZTt||2F 考虑了高阶相似性,论文作者尝试了 Kate Index, Root Page Rank, Common Neighbors, Adamic-Adar Score 等相似性指标,然后把相似性矩阵分解为 S=M−1gMl,因为M−1g 和 Ml 都是稀疏的,所以利用 SVD 能有较高的运行效率。
2.2 Random Walk based
随机游走利用了网络结构采样,在处理大规模网络问题上,常常有很好的性能表现,同时可以很好地刻画网络局部信息。大部分情况下,我们对节点的观察并不需要考虑离它太远的节点,利用局部信息已经能够区别节点间的差异。
DeepWalk&node2vec
DeepWalk 是最早提出的基于 Word2vec 的节点向量化模型。其主要思路,就是利用构造节点在网络上的随机游走路径,来模仿文本生成的过程,提供一个节点序列,再套用 Word2Vec 对每个节点进行向量化表示。因为知道了节点 V 的前 k 个节点和后 k 个节点,就能很好地将网络邻居结构存入向量中。其目标就是最大化 logPr(vi−k,…,vi−1,vi+1,…,vi+k|Zi)。

Node2vec 是对 DeepWalk 的一种更广义的抽象,它引入了 biased-random walks,用来刻画每次随机游走是偏深度探索(DFS)还是广度探索(BFS),分别侧重社区结构和节点重要性的信息。由于 node2vec 有 p 和 q 两个超参数,所以它是一个比较灵活的模型框架。后面也会讲到,它在节点分类问题中有着不俗的表现。
LINE
LINE(Large-scale Information Network Embeddings) 直观上看其实并没有用随机游走。但是[2]将其归类到随机游走的范畴,原因是它和 DeepWalk 的框架类似地应用了概率损失函数。即通过最小化节点 i,j 相连的经验概率 ^p(i,j) 与向量化后两个节点相似性 p(vi,vj) 的距离,并且同时考虑了一阶和二阶相似度(优化两个损失函数),这和随机游走的底层动机是相似的。在实际计算过程中,作者引入了一系列预处理和优化方法(比如负采样),来加快学习性能。

2.3 Deep Learning based
SDNE
SDNE(Structural Deep Network Embeddings) 将节点的相似性向量 si 直接作为模型的输入,通过 Auto-encoder 对这个向量进行降维压缩,得到其向量化后的结果 zi。其损失函数定义为:
L=∑vi∈V||DEC(zi)−si||22
其中 si 是一个|V| 维的输入向量,而 zi 的维数必然远小于前者。其实它的建模思路和前面提到的矩阵分解是一致的,只是在降维时用的不是矩阵分解,而是 Auto-encoder。

另一个模型 DNGR(Deep Neural Graph Representations) 与 SDNE 区别主要在于相似性向量的定义不同,DNGR 将两个节点由随机游走得到的「共同路径」作为衡量其相似性的指标,而 SDNE 直接用一阶关系作为相似性的输入。
这种方法遇到一个较大的问题是,其输入向量维度被限制为|V| ,一方面对网络规模有一定限制,另一方面对新节点的接受程度不好(新节点加入后可能需要重新训练整个网络)。
GCN
前面说的几种模型,大都是利用网络结构对节点进行向量编码。另外有一类方法,强调的更多是将节点本身及其邻居节点的属性(比如文本信息)或特征(比如统计信息)编码进向量中,这类方法可以统称为 Neighborhood Aggregation Algorithms,它们引入了更多特征信息,并且在邻居节点间共享了一些特征或参数。

GCN(Graph Convolutional Networks) 就是其中的一类。上图是 GraphSAGE 算法 [3]的流程步骤。相比 SDNE 类的算法,GCN 的输入向量不必限制在 |V| 维,所以输入数据可以大大减小维数。因为 GCN 在网络结构的基础上,又引入了节点信息,所以在节点分类、链路预测等任务上,比只考虑网络结构的模型有更好的表现,当然这也取决于数据的丰富程度。
3. Evaluation
文章[2]在人工生成网络、社交网络、论文合作网络和蛋白质网络上对几种常见的向量化方法进行了网络重构、节点可视化、链路预测、节点分类的评测,大部分模型实验的输出结果是128维的向量。网络信息如下:

A. Graph Reconstruction

网络重构,是从向量化的节点出发,重新连边构建网络。我们发现 保存了高阶节点关系的模型往往能够更好地重构网络 ,这也符合直观认识。SDNE 几乎在所有数据集上击败了其他模型。
B. Visualization
网络节点可视化,一般是将节点编码成二维或三维的向量,在坐标轴上标注出来。常常会以事实分类区别颜色标记在图像上,用来区分不同向量化方法的好坏。
下图是模型对 SBM 生成网络处理,输出编码至 128 维向量后,再利用 t-SNE 进行压缩得到的二维图像。

当 node2vec 模型设置 BFS 倾向大一些时,可以得到界限很清晰的聚类结果。但是 LE(Laplacian Eigenmaps) 和 GF(Graph Factorization) 模型的效果就比较差强人意了,尤其是 GF 基本不能看。
下图是模型对 Karate 跆拳道俱乐部网络进行二维向量化编码的结果。

从网络结构和节点性质来看,SDNE 和 node2vec 保留了原始网络较多信息。尤其是 SDNE 把节点0单独放到了很远的位置,因为它是社区间的 bridge 节点。而 HOPE 对 0、32、33 的社区中心节点属性刻画的比较好,并且明显地划分出两个社区。GF 的表现依然比较差,除了把度大的节点放在了中心,叶子节点放在了周围,并没有很好的区别社区距离。
C. Link Prediction
在链路预测评估中,各个算法的表现并不是很稳定。这也和模型的设计并不是为特定任务而定制有关。

从 Top k 预测准确性来看,node2vec 模型在 BlogCatelog 数据中表现最好,其他数据集就比较一般(在 PPI 的 Top 表现也不错)。HOPE 模型在 k 比较大时,效果一般在中上位置,比较稳定。
D. Node Classification
作者在 SBM、PPI 和 BlogCatelog 网络上做了节点分类的实验。如下图:

从数据效果来看,node2vec 模型几乎在所有数据集中,都远胜其他模型。原因可能是 node2vec 模型同时刻画了节点的社区结构和网络角色,说明在节点分类中 Random Walk 方法有比较不错的表现。
综上 node2vec 和 SDNE 在除了链路预测问题中,几乎表现都很亮眼。值得重点挖掘!
原文:https://yq.aliyun.com/articles/225331?spm=5176.100239.bloglist.85.YvBIOg

系统学习,进入全球人工智能学院