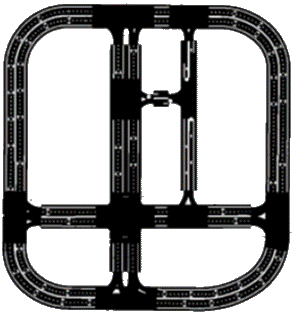
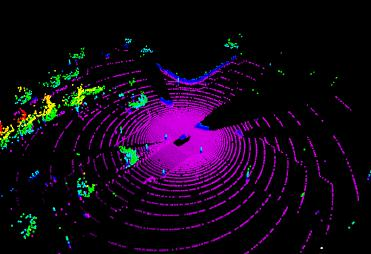
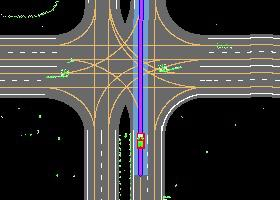
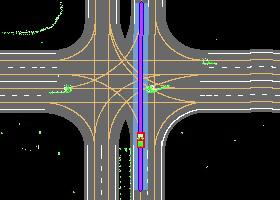
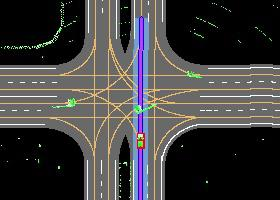
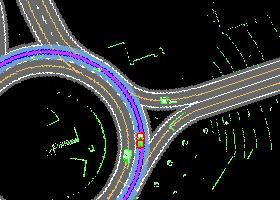
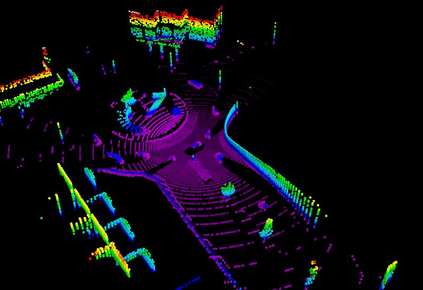
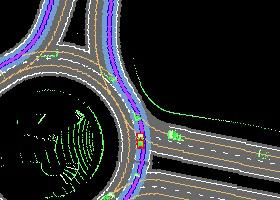
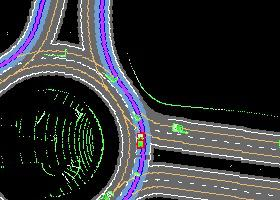
Autonomous driving in urban crowds at unregulated intersections is challenging, where dynamic occlusions and uncertain behaviors of other vehicles should be carefully considered. Traditional methods are heuristic and based on hand-engineered rules and parameters, but scale poorly in new situations. Therefore, they require high labor cost to design and maintain rules in all foreseeable scenarios. Recently, deep reinforcement learning (DRL) has shown promising results in urban driving scenarios. However, DRL is known to be sample inefficient, and most previous works assume perfect observations such as ground-truth locations and motions of vehicles without considering noises and occlusions, which might be a too strong assumption for policy deployment. In this work, we use DRL to train lidar-based end-to-end driving policies that naturally consider imperfect partial observations. We further use unsupervised contrastive representation learning as an auxiliary task to improve the sample efficiency. The comparative evaluation results reveal that our method achieves higher success rates than the state-of-the-art (SOTA) lidar-based end-to-end driving network, better trades off safety and efficiency than the carefully tuned rule-based method, and generalizes better to new scenarios than the baselines. Demo videos are available at https://caipeide.github.io/carl-lead/.
翻译:在不受监管的十字路口,城市人群中自主驾驶是具有挑战性的,应仔细考虑其他车辆动态排斥和不确定行为。传统方法是超常的,基于手工设计的规则和参数,但在新情况下规模不高。因此,在所有可预见的情景中,设计和维护规则都需要高劳动力成本。最近,深度强化学习(DRL)在城市驾驶情景中显示出了有希望的结果。但据知,DRL的样本效率低下,而大多数以前的工作假设是完美的观察,如地面真实位置和车辆移动,而不考虑噪音和隐蔽,这可能是政策部署的一个过于强烈的假设。在这项工作中,我们使用DRL来培训基于LDAR的终端到终端驱动政策,这些政策自然考虑到不完善的部分观察。我们进一步使用非超强的对比代表性学习作为提高抽样效率的辅助任务。比较评价结果显示,我们的方法比State-the-art(SOudar-led-end-end)终端驱动网络的成功率更高,这或许是政策部署的有力假设。我们使用DLL来训练安全与效率更好的交易,比仔细调整规则/demodemodeal-deal-mab-de-deb-develisab-de-de-droisab-droismismismisldaldal as)比现有的基准/gal-viewdal-view/d-degal-dal-degal-dal-dal-dal-dal-dalismismismaps制制制制制制制制制制制制制制制制式方法更好。