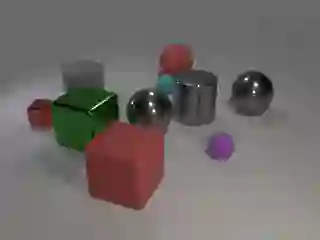We introduce CLEVR-Math, a multi-modal math word problems dataset consisting of simple math word problems involving addition/subtraction, represented partly by a textual description and partly by an image illustrating the scenario. The text describes actions performed on the scene that is depicted in the image. Since the question posed may not be about the scene in the image, but about the state of the scene before or after the actions are applied, the solver envision or imagine the state changes due to these actions. Solving these word problems requires a combination of language, visual and mathematical reasoning. We apply state-of-the-art neural and neuro-symbolic models for visual question answering on CLEVR-Math and empirically evaluate their performances. Our results show how neither method generalise to chains of operations. We discuss the limitations of the two in addressing the task of multi-modal word problem solving.
翻译:我们引入了多模式数学词问题数据集CLEVR-Math, 这是一个多模式数学词问题数据集, 由包含添加/ 减缩的简单数学词问题组成, 部分以文字描述为代表, 部分以描述情景的图像为代表。 文本描述了在图像中描述的现场行动。 由于提出的问题可能不是图像中的场景, 而是行动实施之前或之后的场景状况, 解答者设想或想象由于这些行动而导致的状态变化。 解决这些问题需要语言、 视觉和数学的推理结合。 我们应用最先进的神经和神经- 精神- 同步模型来解答 CLEVR- Math 的视觉问题, 并用实验性的方法评估其表现。 我们的结果显示, 无论是如何用方法概括操作链。 我们讨论这两个词在解决多模式词问题的任务方面的局限性 。