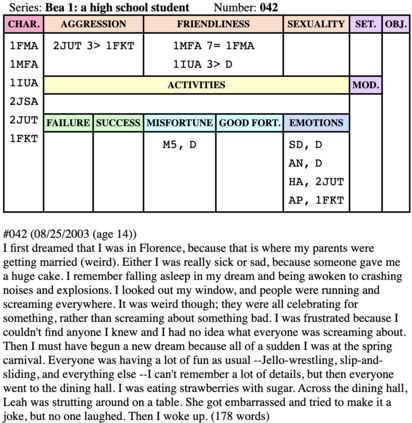
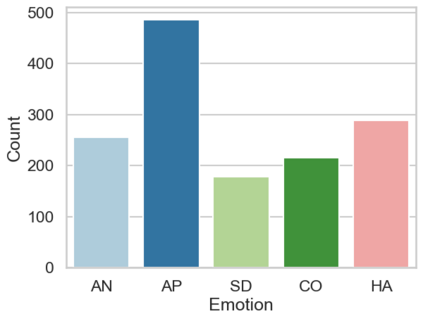
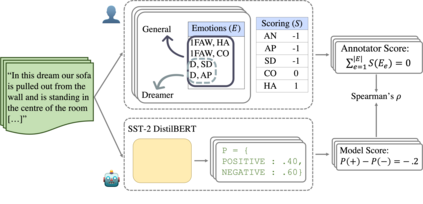
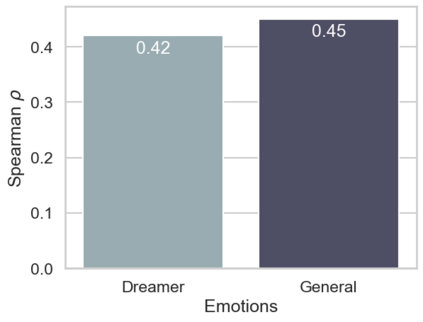
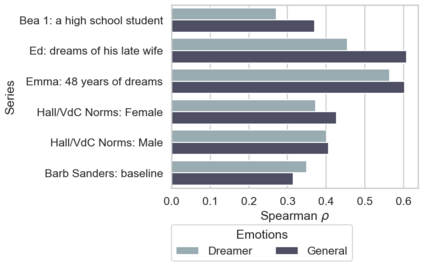
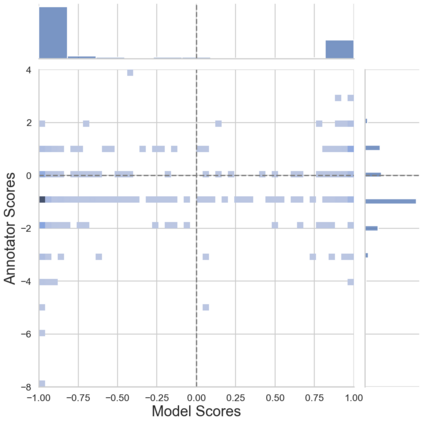
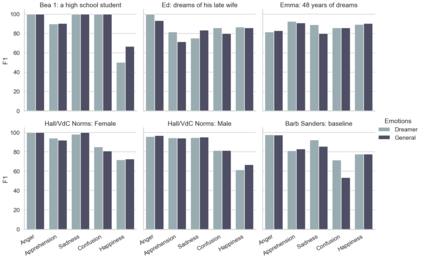
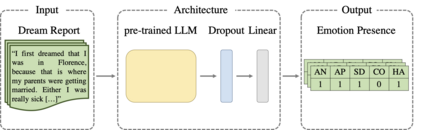
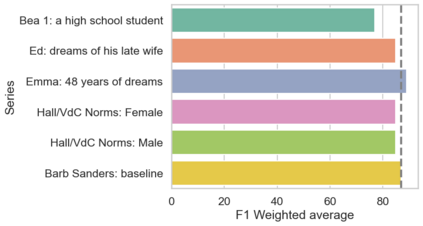
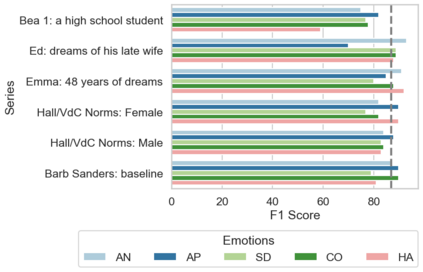
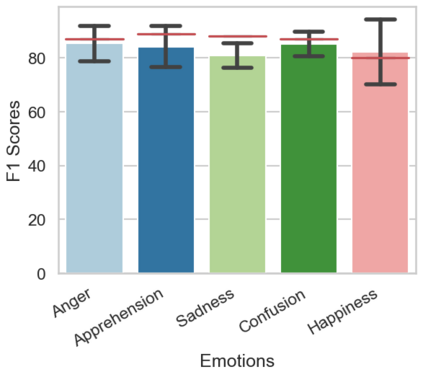
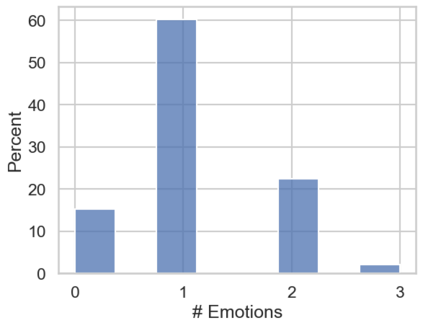
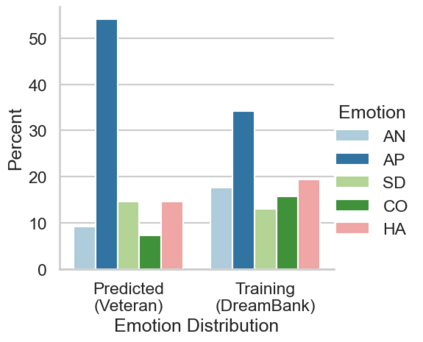
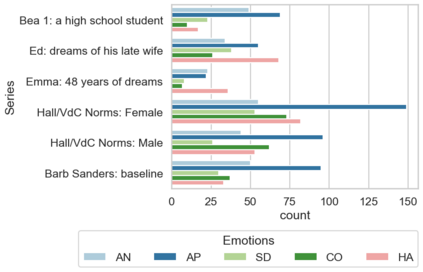
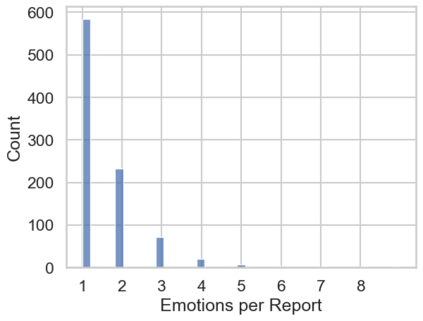
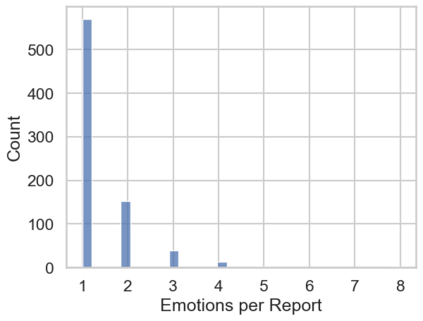
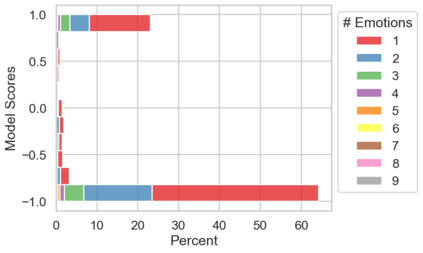
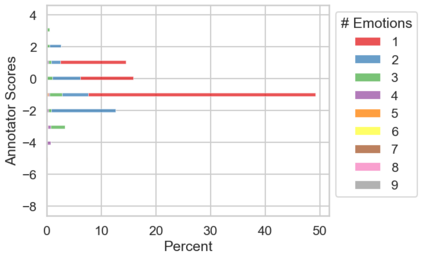
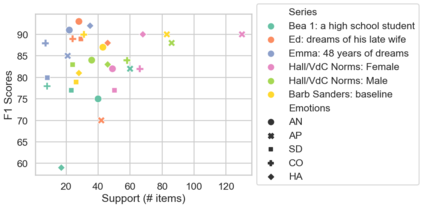
In the field of dream research, the study of dream content typically relies on the analysis of verbal reports provided by dreamers upon awakening from their sleep. This task is classically performed through manual scoring provided by trained annotators, at a great time expense. While a consistent body of work suggests that natural language processing (NLP) tools can support the automatic analysis of dream reports, proposed methods lacked the ability to reason over a report's full context and required extensive data pre-processing. Furthermore, in most cases, these methods were not validated against standard manual scoring approaches. In this work, we address these limitations by adopting large language models (LLMs) to study and replicate the manual annotation of dream reports, using a mixture of off-the-shelf and bespoke approaches, with a focus on references to reports' emotions. Our results show that the off-the-shelf method achieves a low performance probably in light of inherent linguistic differences between reports collected in different (groups of) individuals. On the other hand, the proposed bespoke text classification method achieves a high performance, which is robust against potential biases. Overall, these observations indicate that our approach could find application in the analysis of large dream datasets and may favour reproducibility and comparability of results across studies.
翻译:在梦想研究领域,对梦想内容的研究通常依赖于对梦梦者从睡眠醒来时醒醒醒时提供的口头报告的分析,对梦内容的研究通常依赖对梦梦者从睡梦中醒来时提供的口头报告的分析,这一任务典型地由经过训练的助记员提供人工评分,在花费大量时间的情况下,由经过训练的助记员提供人工评分,以巨大的时间费用来完成。虽然一系列一致的工作表明,自然语言处理工具可以支持对梦报告进行自动分析,但拟议方法缺乏根据报告全部背景进行理性思考的能力,需要广泛的数据预处理;此外,在多数情况下,这些方法没有参照标准的手册评分方法加以验证;在这项工作中,我们采用大型语言模型(LLLLMMs)来研究这些局限性,研究并复制对梦想报告进行手工注释的人工说明,同时采用现成口和口述的混合方法,以报告情感为重点。我们的结果显示,由于不同(群体)个人收集的报告之间存在固有的语言差异,因此拟议中的文本分类方法可能达到很高的成绩,这是针对潜在偏偏偏的强的成绩。总体而言,这些观察表明,我们的方法和在分析中可以找到在大梦想研究中进行数据分析时的比较结果和结果和结果和大分析中的应用。</s>