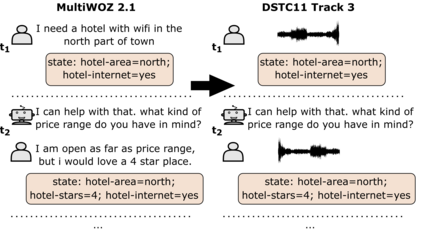
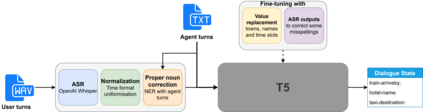
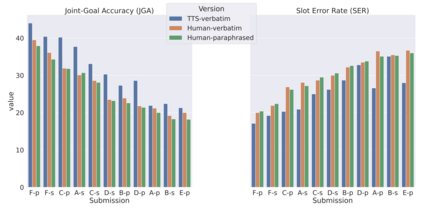
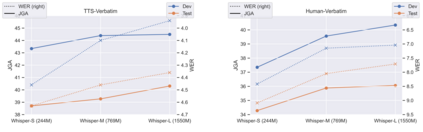
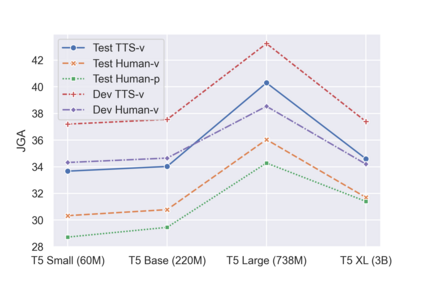
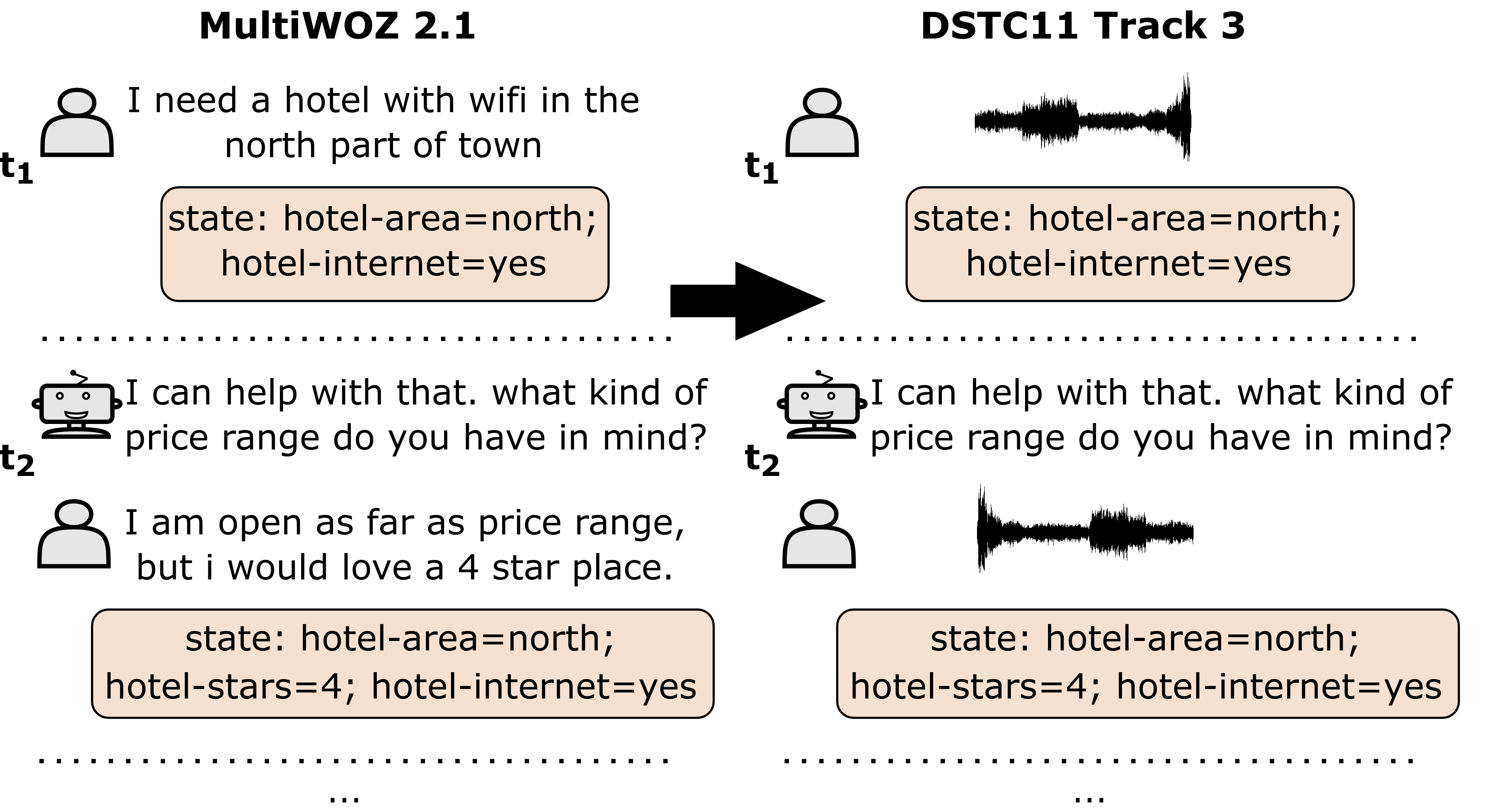
Though Dialogue State Tracking (DST) is a core component of spoken dialogue systems, recent work on this task mostly deals with chat corpora, disregarding the discrepancies between spoken and written language.In this paper, we propose OLISIA, a cascade system which integrates an Automatic Speech Recognition (ASR) model and a DST model. We introduce several adaptations in the ASR and DST modules to improve integration and robustness to spoken conversations.With these adaptations, our system ranked first in DSTC11 Track 3, a benchmark to evaluate spoken DST. We conduct an in-depth analysis of the results and find that normalizing the ASR outputs and adapting the DST inputs through data augmentation, along with increasing the pre-trained models size all play an important role in reducing the performance discrepancy between written and spoken conversations.
翻译:暂无翻译