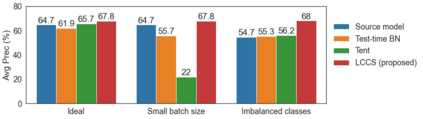
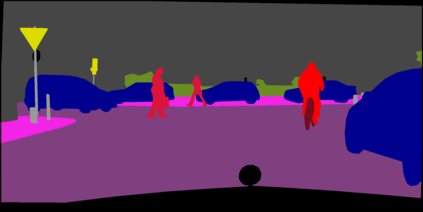
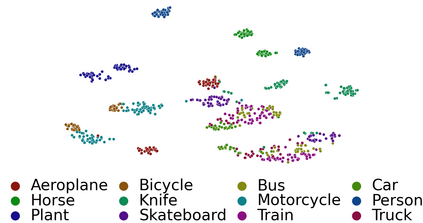
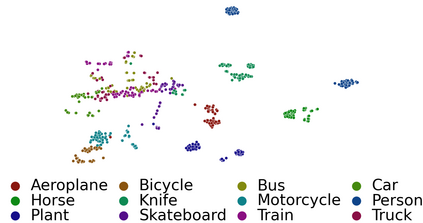
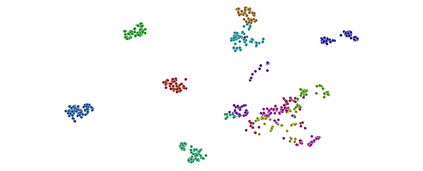
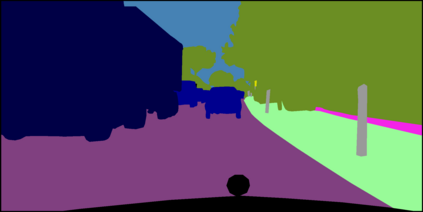
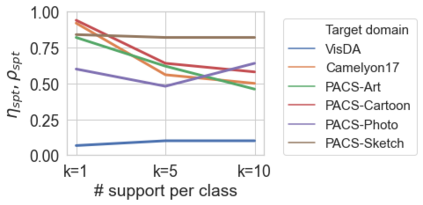
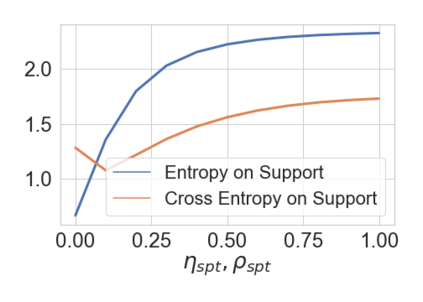
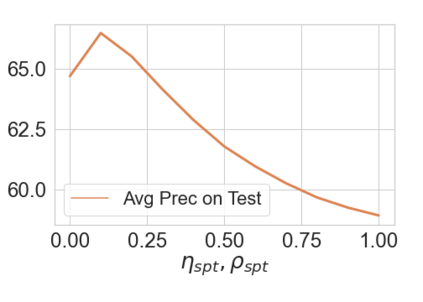
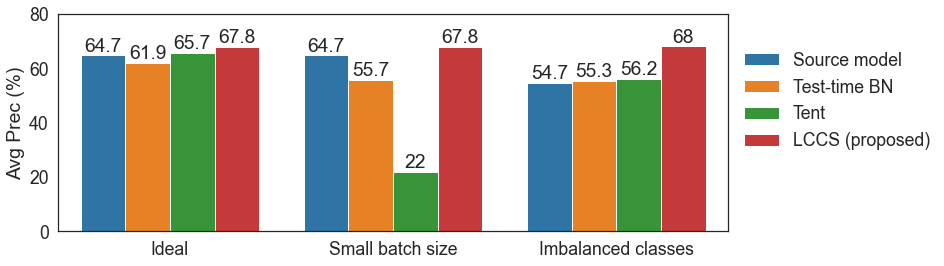
Deep networks are prone to performance degradation when there is a domain shift between the source (training) data and target (test) data. Recent test-time adaptation methods update batch normalization layers of pre-trained source models deployed in new target environments with streaming data to mitigate such performance degradation. Although such methods can adapt on-the-fly without first collecting a large target domain dataset, their performance is dependent on streaming conditions such as mini-batch size and class-distribution, which can be unpredictable in practice. In this work, we propose a framework for few-shot domain adaptation to address the practical challenges of data-efficient adaptation. Specifically, we propose a constrained optimization of feature normalization statistics in pre-trained source models supervised by a small support set from the target domain. Our method is easy to implement and improves source model performance with as few as one sample per class for classification tasks. Extensive experiments on 5 cross-domain classification and 4 semantic segmentation datasets show that our method achieves more accurate and reliable performance than test-time adaptation, while not being constrained by streaming conditions.
翻译:当源(培训)数据和目标(测试)数据发生域变时,深网络容易出现性能退化。最近的测试-时间适应方法更新了在新目标环境中部署的经过培训的源模型的批次正常化层,并附有流数据以缓解这种性能退化。虽然这些方法可以在不首先收集大型目标域数据集的情况下在现场适应,但其性能取决于流态条件,如小型批量大小和分类分布,这在实践中可能无法预测。在这项工作中,我们建议了一个“微小”域适应框架,以应对数据效率适应的实际挑战。具体地说,我们建议限制在目标领域一组小支持监督下对经过培训的源模型中地貌正常化统计数据的优化。我们的方法是易于执行和改进源模型的性能,而每个分类任务只采集一个样本。关于5个跨界分类和4个语系分解数据集的广泛实验表明,我们的方法比测试-时间适应更准确和可靠,而不受流流条件的限制。