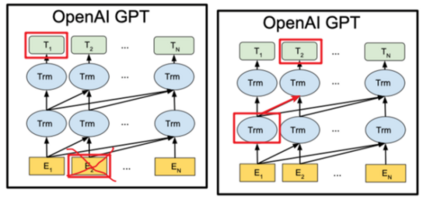
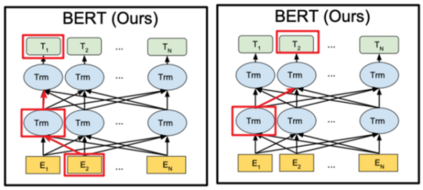
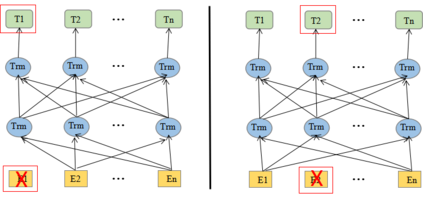
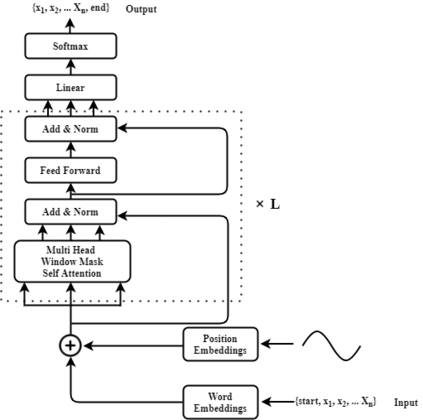
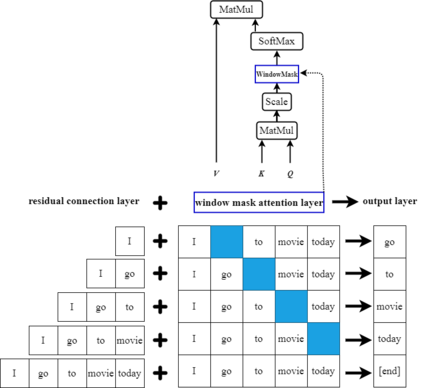
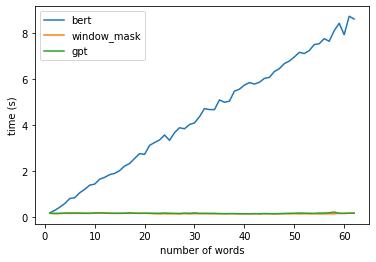
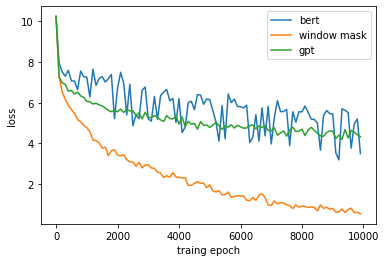
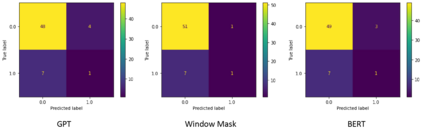
In recent years BERT shows apparent advantages and great potential in natural language processing tasks. However, both training and applying BERT requires intensive time and resources for computing contextual language representations, which hinders its universality and applicability. To overcome this bottleneck, we propose a deep bidirectional language model by using window masking mechanism at attention layer. This work computes contextual language representations without random masking as does in BERT and maintains the deep bidirectional architecture like BERT. To compute the same sentence representation, our method shows O(n) complexity less compared to other transformer-based models with O($n^2$). To further demonstrate its superiority, computing context language representations on CPU environments is conducted, by using the embeddings from the proposed method, logistic regression shows much higher accuracy in terms of SMS classification. Moverover, the proposed method also achieves significant higher performance in semantic similarity tasks.
翻译:近年来,BERT在自然语言处理任务中显示出明显的优势和巨大潜力。然而,培训和应用BERT都需要大量的时间和资源来计算背景语言代表,这妨碍了其普遍性和适用性。为了克服这一瓶颈,我们提议通过在注意力层使用窗口遮蔽机制来建立深度双向语言模式。这项工作在没有随机掩蔽的情况下计算背景语言代表,而没有像BERT那样随机遮蔽,并维持像BERT那样的深度双向结构。要计算相同的句号代表,我们的方法显示O(n)复杂性比以O(n)2美元的其他变压器模型要低。为了进一步证明其优越性,在CPU环境中进行计算背景语言代表,通过使用拟议方法的嵌入式,后勤回归显示SMS分类的准确性要高得多。移动器,拟议方法在语义相似任务方面也取得了显著的更高性能。