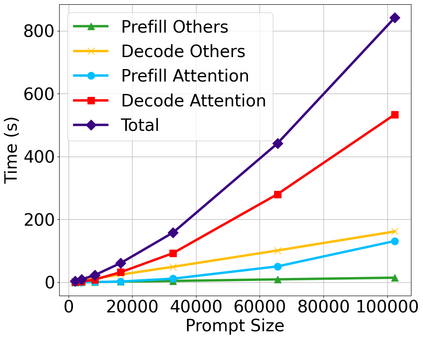
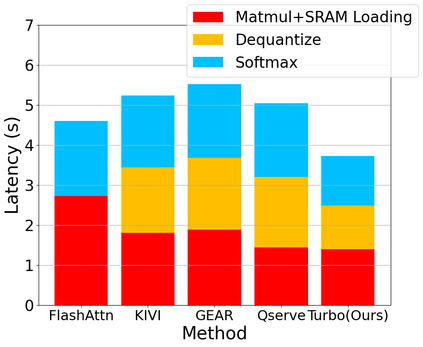
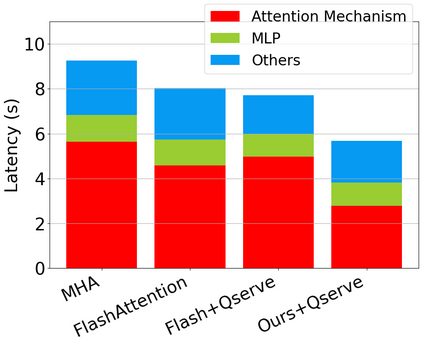
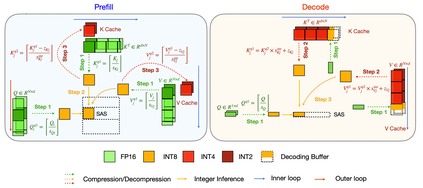
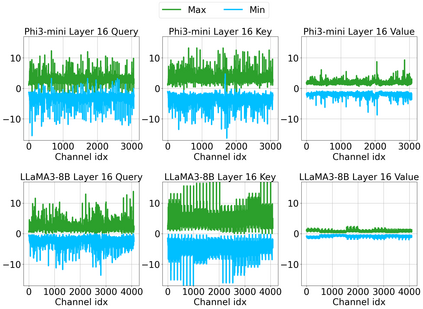
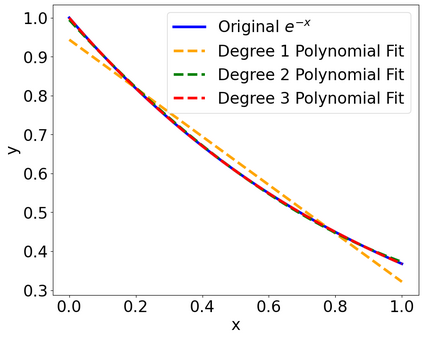
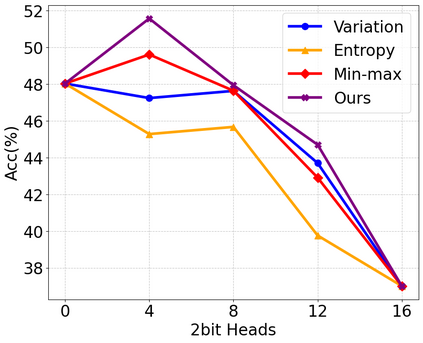
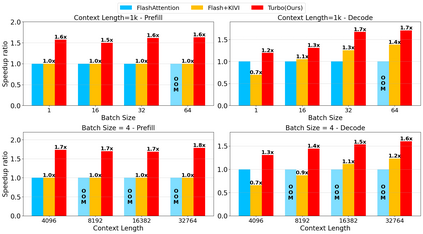
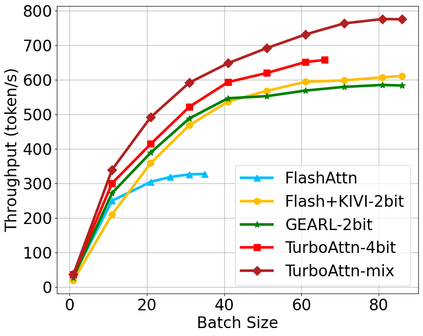
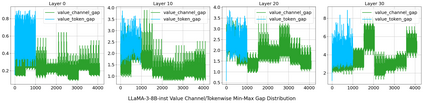
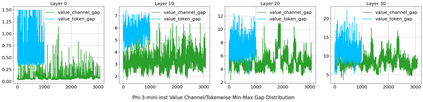
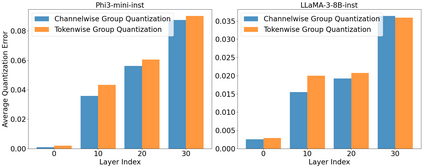
Large language model (LLM) inference demands significant amount of computation and memory, especially in the key attention mechanism. While techniques, such as quantization and acceleration algorithms, like FlashAttention, have improved efficiency of the overall inference, they address different aspects of the problem: quantization focuses on weight-activation operations, while FlashAttention improves execution but requires high-precision formats. Recent Key-value (KV) cache quantization reduces memory bandwidth but still needs floating-point dequantization for attention operation. We present TurboAttention, a comprehensive approach to enable quantized execution of attention that simultaneously addresses both memory and computational efficiency. Our solution introduces two key innovations: FlashQ, a headwise attention quantization technique that enables both compression of KV cache and quantized execution of activation-activation multiplication, and Sparsity-based Softmax Approximation (SAS), which eliminates the need for dequantization to FP32 during exponentiation operation in attention. Experimental results demonstrate that TurboAttention achieves 1.2-1.8x speedup in attention, reduces the KV cache size by over 4.4x, and enables up to 2.37x maximum throughput over the FP16 baseline while outperforming state-of-the-art quantization and compression techniques across various datasets and models.
翻译:暂无翻译