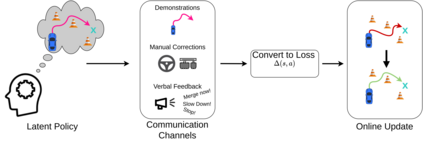
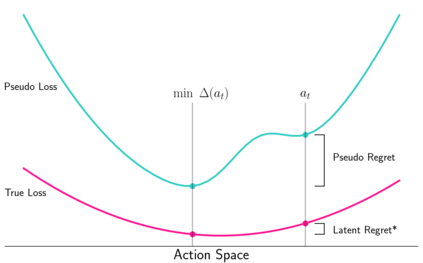
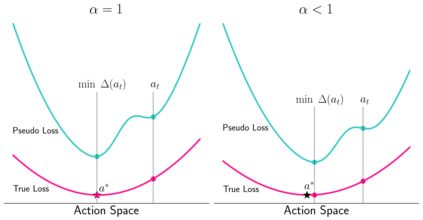
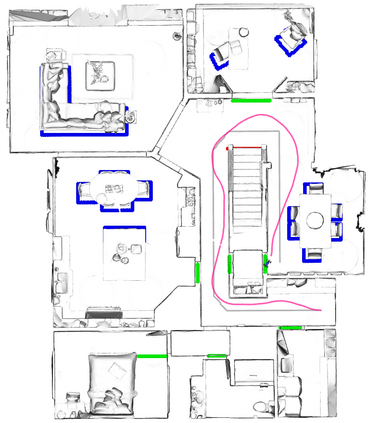
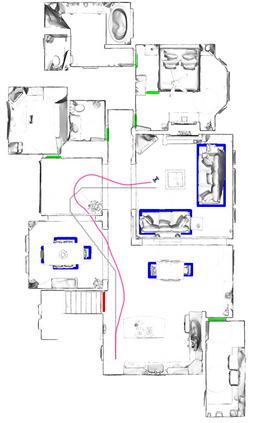
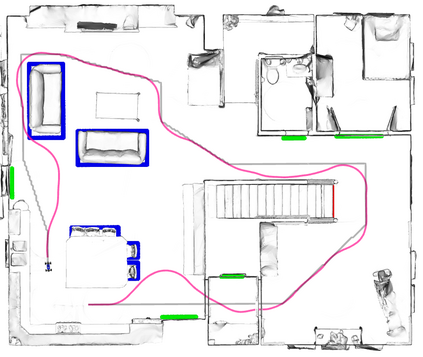
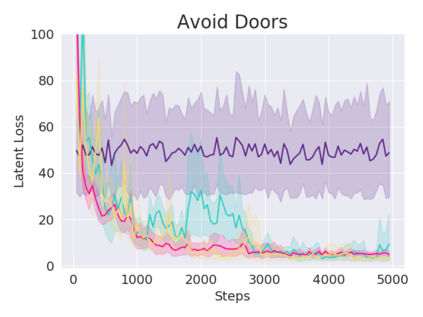
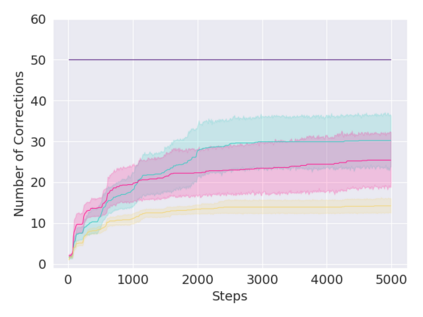
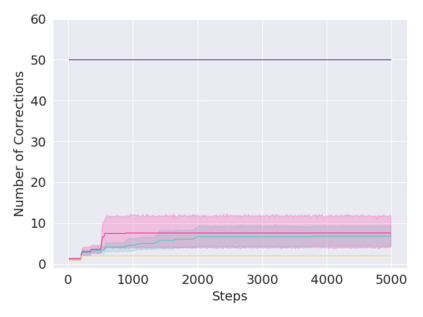
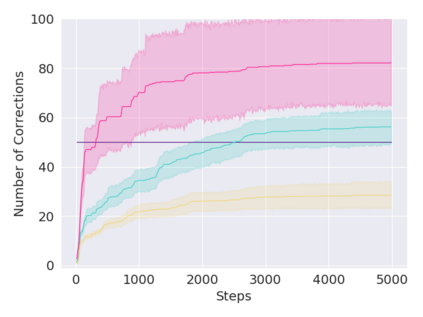
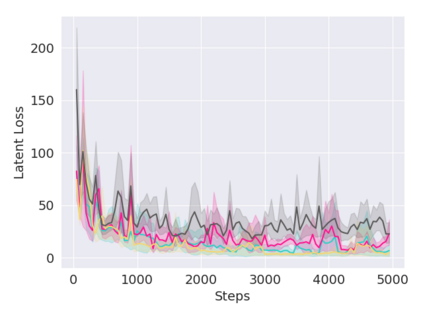
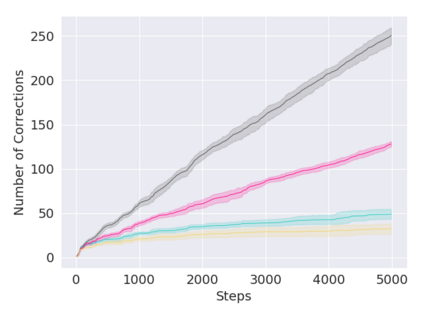
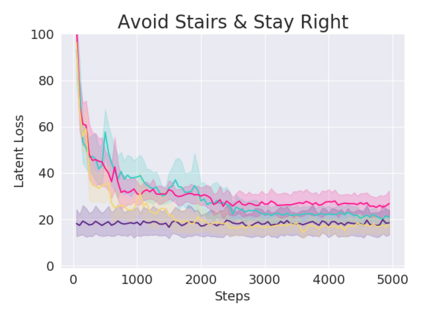
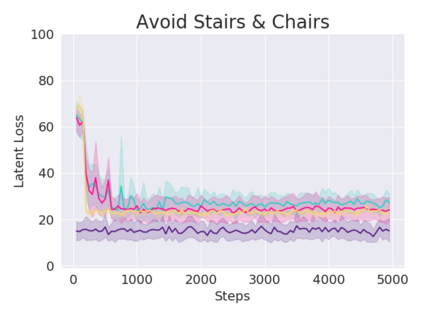
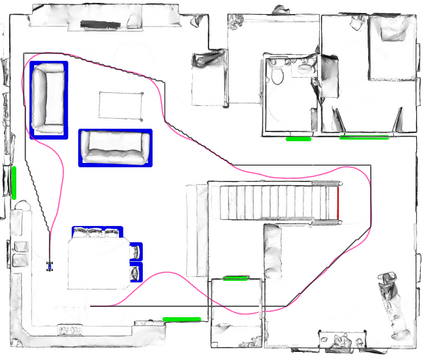
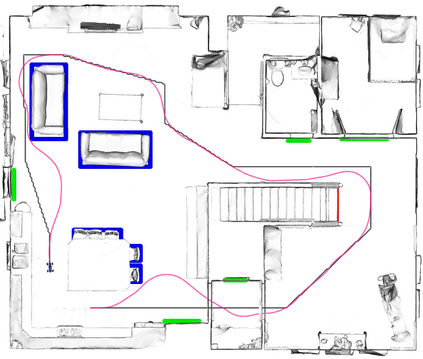
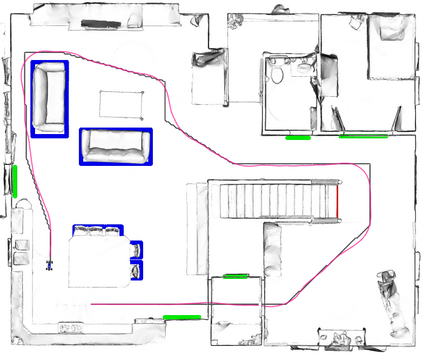
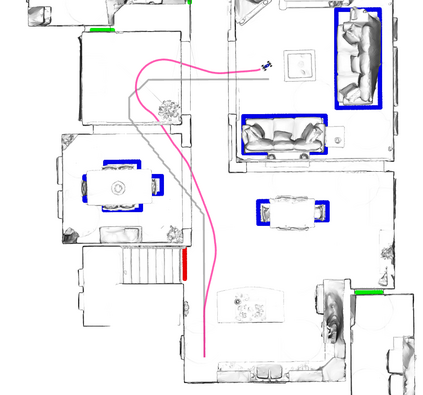
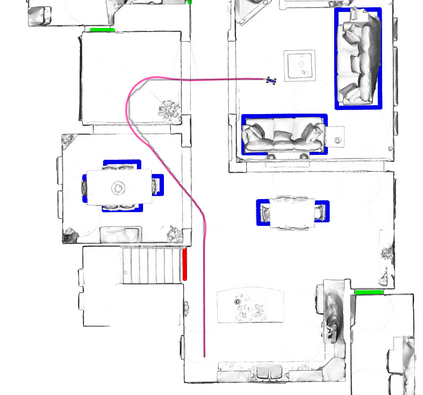
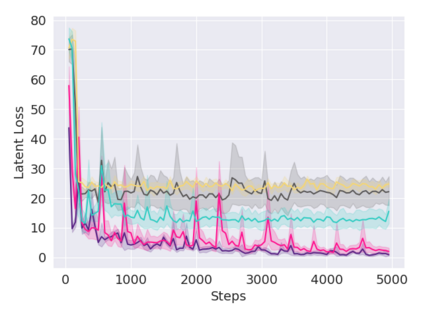
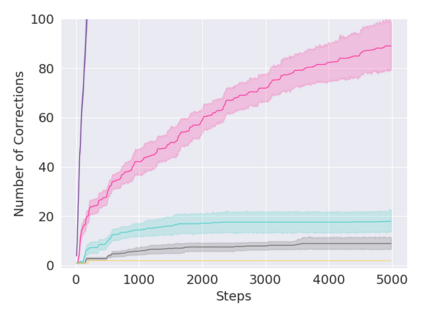
A key challenge in Imitation Learning (IL) is that optimal state actions demonstrations are difficult for the teacher to provide. For example in robotics, providing kinesthetic demonstrations on a robotic manipulator requires the teacher to control multiple degrees of freedom at once. The difficulty of requiring optimal state action demonstrations limits the space of problems where the teacher can provide quality feedback. As an alternative to state action demonstrations, the teacher can provide corrective feedback such as their preferences or rewards. Prior work has created algorithms designed to learn from specific types of noisy feedback, but across teachers and tasks different forms of feedback may be required. Instead we propose that in order to learn from a diversity of scenarios we need to learn from a variety of feedback. To learn from a variety of feedback we make the following insight: the teacher's cost function is latent and we can model a stream of feedback as a stream of loss functions. We then use any online learning algorithm to minimize the sum of these losses. With this insight we can learn from a diversity of feedback that is weakly correlated with the teacher's true cost function. We unify prior work into a general corrective feedback meta-algorithm and show that regardless of feedback we can obtain the same regret bounds. We demonstrate our approach by learning to perform a household navigation task on a robotic racecar platform. Our results show that our approach can learn quickly from a variety of noisy feedback.
翻译:模拟学习(IL)中的一个关键挑战是,教师很难提供最佳状态行动演示。例如,在机器人中,提供机器人操纵器的动画演示要求教师同时控制多种程度的自由。要求优化状态行动演示的困难限制了教师提供高质量反馈的问题空间。作为州行动演示的替代办法,教师可以提供纠正性反馈,如他们的偏好或奖励。先前的工作创造了各种算法,旨在从特定类型的噪音反馈中学习,但可能需要在教师和不同形式的反馈中学习。相反,我们提议,为了从多种情景中学习我们需要从各种反馈中学习的动画演示,教师需要同时控制多种程度的自由。为了从各种反馈中学习各种反馈:教师的成本功能是潜在的,我们可以将一系列反馈作为损失功能的流来模拟。我们随后使用任何在线学习算法来尽量减少这些损失的总和。我们可以从与教师的真正成本功能关系不大的多种反馈中学习。我们把先前的工作整合为一般的纠正性反馈,需要从各种反馈中学习各种反馈。我们要从以下的洞见:教师的成本功能是潜在的,我们可以用一种学习我们家动式的动力学习方法。