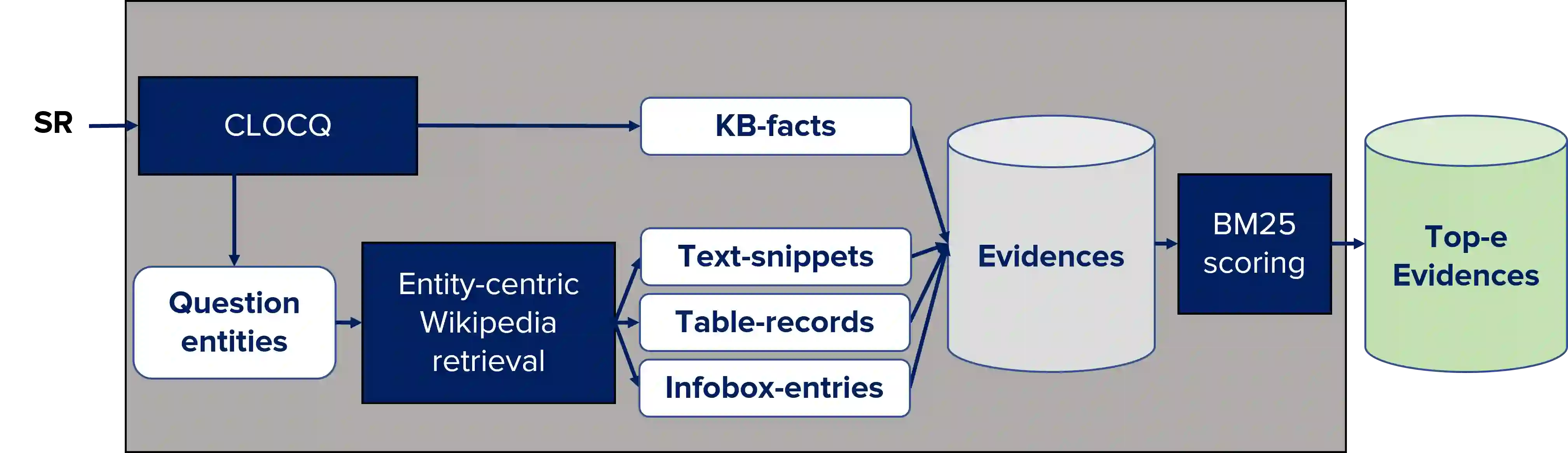
Conversational question answering (ConvQA) tackles sequential information needs where contexts in follow-up questions are left implicit. Current ConvQA systems operate over homogeneous sources of information: either a knowledge base (KB), or a text corpus, or a collection of tables. This paper addresses the novel issue of jointly tapping into all of these together, this way boosting answer coverage and confidence. We present CONVINSE, an end-to-end pipeline for ConvQA over heterogeneous sources, operating in three stages: i) learning an explicit structured representation of an incoming question and its conversational context, ii) harnessing this frame-like representation to uniformly capture relevant evidences from KB, text, and tables, and iii) running a fusion-in-decoder model to generate the answer. We construct and release the first benchmark, ConvMix, for ConvQA over heterogeneous sources, comprising 3000 real-user conversations with 16000 questions, along with entity annotations, completed question utterances, and question paraphrases. Experiments demonstrate the viability and advantages of our method, compared to state-of-the-art baselines.
翻译:当前的ConvQA系统运行于同一信息来源:知识库(KB)或文本库,或表格汇编。本文涉及共同利用所有这些知识库的新问题,这样就可以提高答案的覆盖面和信任度。我们介绍Convinste,Convinse是ConvQA对不同来源的端至端管道,分三个阶段运作:i)学习对一个问题及其谈话背景的明确结构化表述;ii)利用这种框架式表述方式统一收集来自KB、文本和表格的相关证据;iii)运行一个聚合-分解模型来生成答案。我们为ConvQA构建和发布第一个基准,ConvMix,用于ConqA对各种来源的组合,包括3000个实际用户与16000个问题的对话,以及实体说明、完成的问题和问题解说。实验表明我们的方法与状态基线相比的可行性和优势。