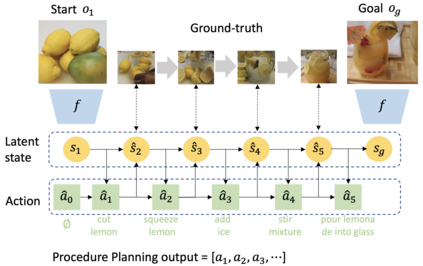
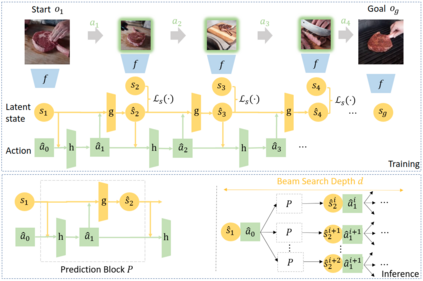
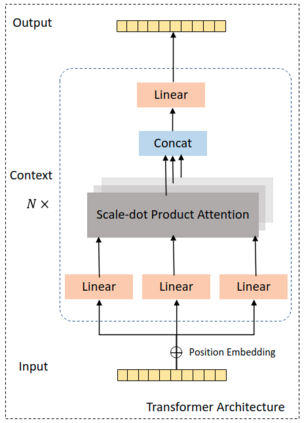
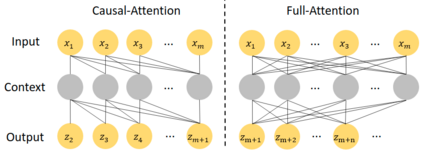
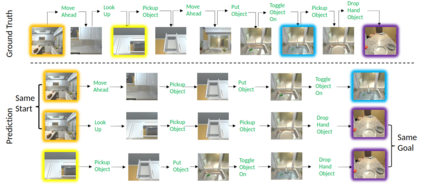
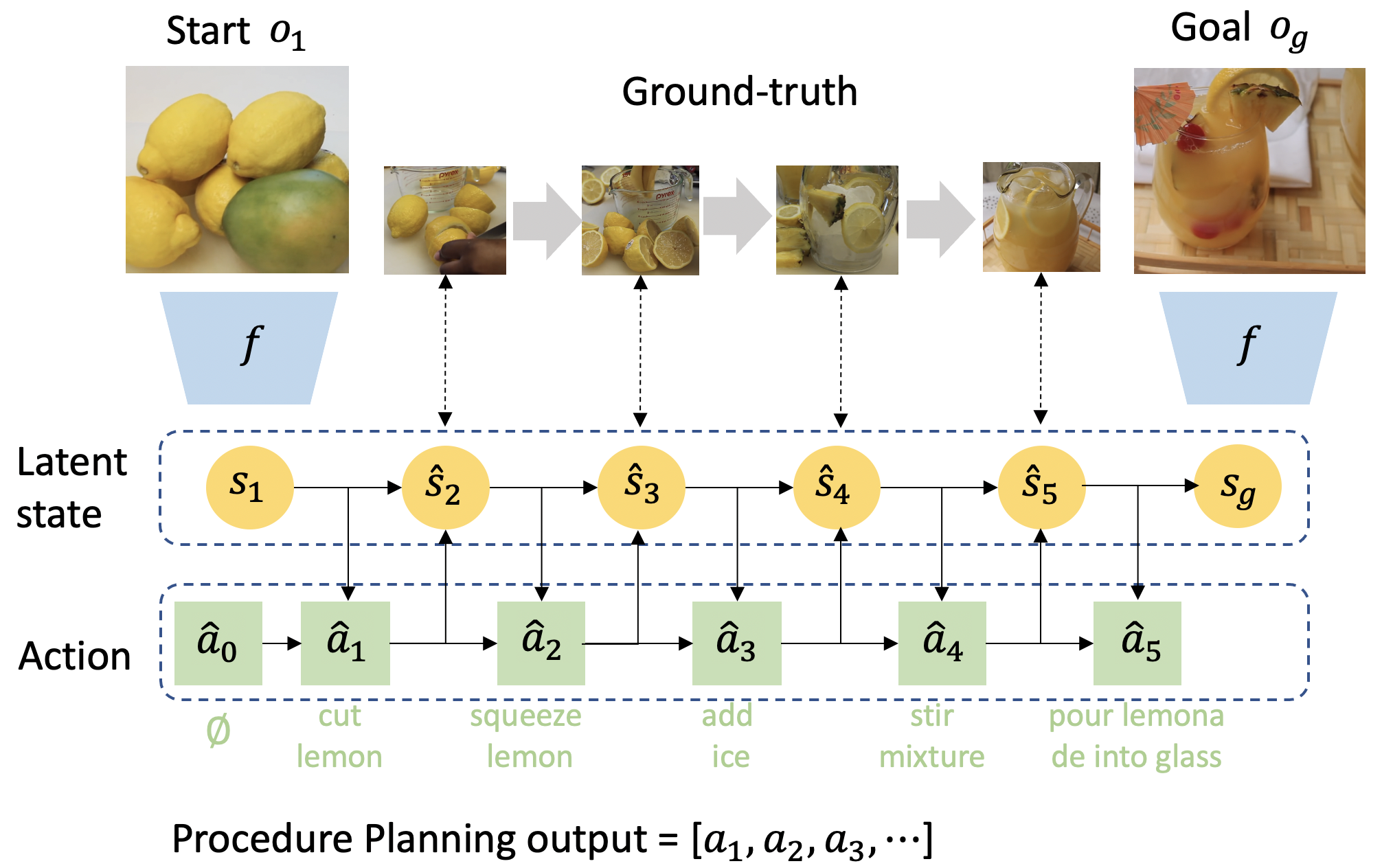
In this work, we study the problem of how to leverage instructional videos to facilitate the understanding of human decision-making processes, focusing on training a model with the ability to plan a goal-directed procedure from real-world videos. Learning structured and plannable state and action spaces directly from unstructured videos is the key technical challenge of our task. There are two problems: first, the appearance gap between the training and validation datasets could be large for unstructured videos; second, these gaps lead to decision errors that compound over the steps. We address these limitations with Planning Transformer (PlaTe), which has the advantage of circumventing the compounding prediction errors that occur with single-step models during long model-based rollouts. Our method simultaneously learns the latent state and action information of assigned tasks and the representations of the decision-making process from human demonstrations. Experiments conducted on real-world instructional videos and an interactive environment show that our method can achieve a better performance in reaching the indicated goal than previous algorithms. We also validated the possibility of applying procedural tasks on a UR-5 platform.
翻译:在这项工作中,我们研究了如何利用教学视频促进理解人类决策进程的问题,重点是培训一个能够从现实世界视频中规划目标导向程序的模型。从非结构化视频直接学习结构化和可规划状态和行动空间是我们任务的关键技术挑战。有两个问题:第一,培训和验证数据集之间的表面差距对于非结构化视频来说可能很大;第二,这些差距导致决定错误,使步骤复杂化。我们与规划变换器(PlaTe)解决了这些限制,规划变换器(PlaTe)的优势是绕过在长期模型推出过程中与单步模式一起出现的复合预测错误。我们的方法同时学习了分配任务的潜在状态和行动信息以及人类演示对决策进程的表述。对现实世界教学视频和互动环境的实验表明,我们的方法在实现既定目标方面可以比以往的算法取得更好的表现。我们还验证了在UR-5平台上应用程序任务的可能性。