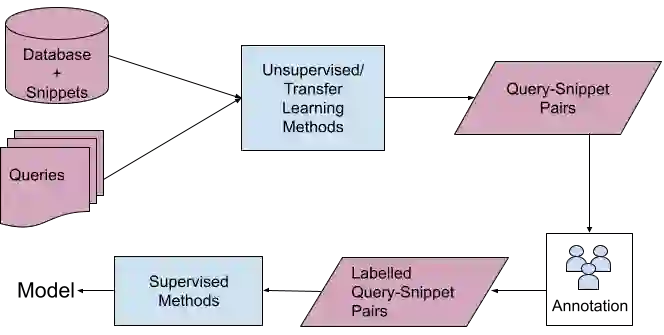
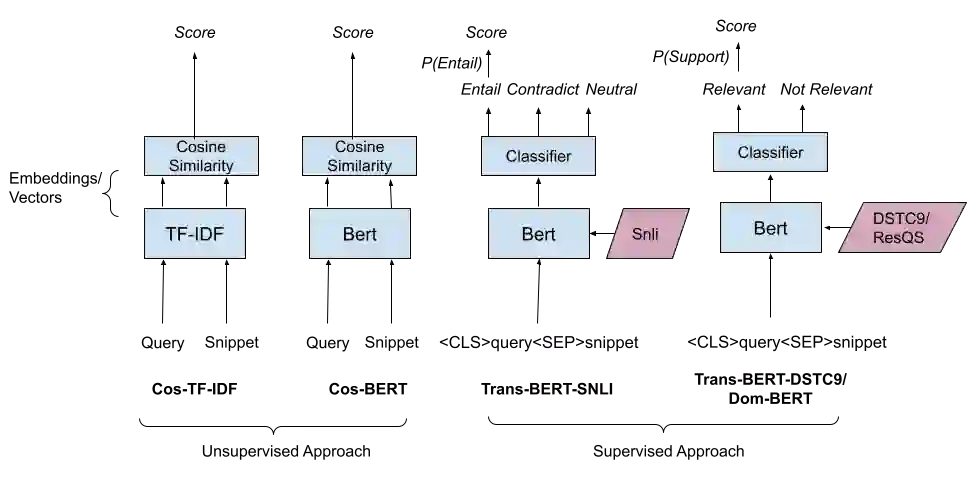
A user input to a schema-driven dialogue information navigation system, such as venue search, is typically constrained by the underlying database which restricts the user to specify a predefined set of preferences, or slots, corresponding to the database fields. We envision a more natural information navigation dialogue interface where a user has flexibility to specify unconstrained preferences that may not match a predefined schema. We propose to use information retrieval from unstructured knowledge to identify entities relevant to a user request. We update the Cambridge restaurants database with unstructured knowledge snippets (reviews and information from the web) for each of the restaurants and annotate a set of query-snippet pairs with a relevance label. We use the annotated dataset to train and evaluate snippet relevance classifiers, as a proxy to evaluating recommendation accuracy. We show that with a pretrained transformer model as an encoder, an unsupervised/supervised classifier achieves a weighted F1 of .661/.856.
翻译:系统驱动的对话信息导航系统的用户输入,例如地点搜索,通常受到基本数据库的限制,数据库限制用户指定一套与数据库字段相对应的预定偏好或空档。我们设想了一个更自然的信息导航对话界面,用户可以灵活地指定不受限制的偏好,而这种偏好可能与预定义的图案不匹配。我们提议使用非结构化知识的信息检索,以识别与用户请求相关的实体。我们更新剑桥餐厅数据库,为每个餐馆提供非结构化的知识片片段(审查和网上信息),并注明一组带有相关标签的查询片配对。我们使用附加说明的数据集来训练和评价片段关联性分类器,作为评价建议准确性的替代物。我们显示,用预先训练的变压器模型作为编码器,一个未经监督/监督的分类器可实现加权F1,即为.661/856。