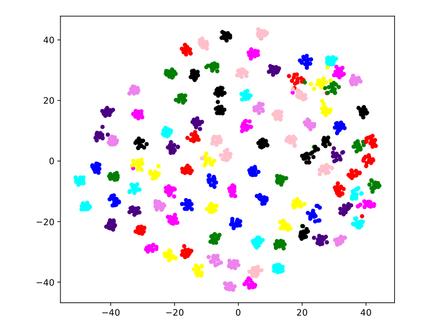
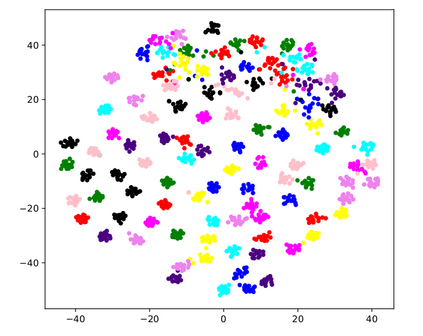
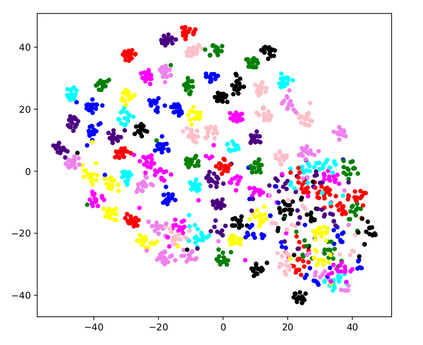
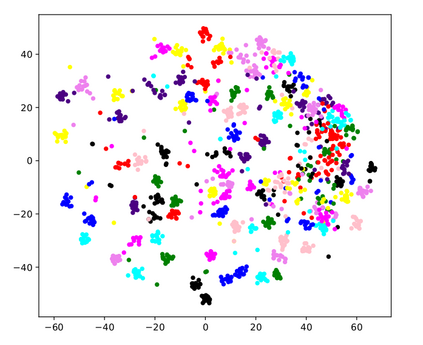
Many modern computer vision algorithms suffer from two major bottlenecks: scarcity of data and learning new tasks incrementally. While training the model with new batches of data the model looses it's ability to classify the previous data judiciously which is termed as catastrophic forgetting. Conventional methods have tried to mitigate catastrophic forgetting of the previously learned data while the training at the current session has been compromised. The state-of-the-art generative replay based approaches use complicated structures such as generative adversarial network (GAN) to deal with catastrophic forgetting. Additionally, training a GAN with few samples may lead to instability. In this work, we present a novel method to deal with these two major hurdles. Our method identifies a better embedding space with an improved contrasting loss to make classification more robust. Moreover, our approach is able to retain previously acquired knowledge in the embedding space even when trained with new classes. We update previous session class prototypes while training in such a way that it is able to represent the true class mean. This is of prime importance as our classification rule is based on the nearest class mean classification strategy. We have demonstrated our results by showing that the embedding space remains intact after training the model with new classes. We showed that our method preformed better than the existing state-of-the-art algorithms in terms of accuracy across different sessions.
翻译:许多现代计算机视觉算法存在两大瓶颈:缺乏数据,学习新任务。模型在用新批数据对模型进行新数据培训时,松散了对先前数据进行明智分类的能力,被称之为灾难性的遗忘。常规方法试图减轻灾难性地忘记先前所学到的数据,而本届会议的培训则受到影响。最先进的基因重现方法使用复杂的结构,如基因对抗网络(GAN)来处理灾难性的遗忘。此外,用少量样本对GAN进行培训可能导致不稳定。在这项工作中,我们提出了一个应对这两个主要障碍的新方法。我们的方法确定了一个更好的嵌入空间,以更好的对比损失使分类更加稳健。此外,我们的方法能够将先前获得的知识保留在嵌入空间,即使经过新课程培训时,我们也能保留在嵌入空间中。我们更新了前班的原型,而培训能够代表真正的阶级。这非常重要,因为我们的分类规则是以最近的类平均分类战略为基础。我们展示了我们的成果,我们展示了在新的课程中展示了比新的培训课程更精确性的方法。