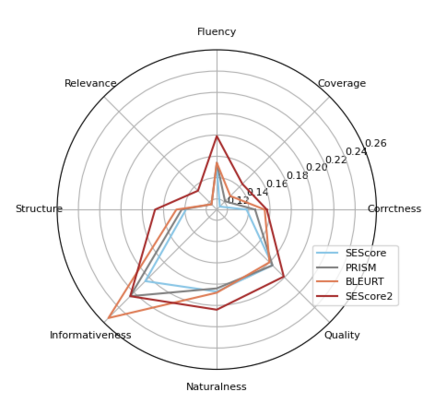
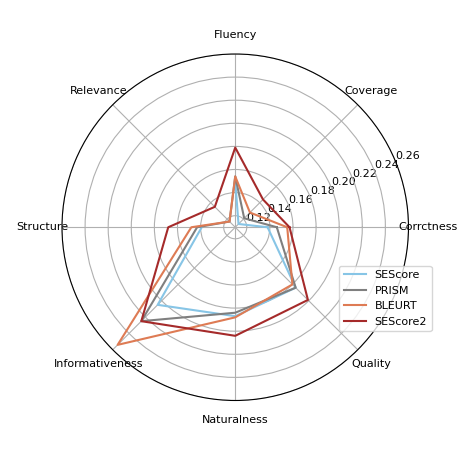
Is it possible to train a general metric for evaluating text generation quality without human annotated ratings? Existing learned metrics either perform unsatisfactorily across text generation tasks or require human ratings for training on specific tasks. In this paper, we propose SESCORE2, a self-supervised approach for training a model-based metric for text generation evaluation. The key concept is to synthesize realistic model mistakes by perturbing sentences retrieved from a corpus. The primary advantage of the SESCORE2 is its ease of extension to many other languages while providing reliable severity estimation. We evaluate SESCORE2 and previous methods on four text generation tasks across three languages. SESCORE2 outperforms unsupervised metric PRISM on four text generation evaluation benchmarks, with a Kendall improvement of 0.078. Surprisingly, SESCORE2 even outperforms the supervised BLEURT and COMET on multiple text generation tasks. The code and data are available at https://github.com/xu1998hz/SEScore2.
翻译:暂无翻译