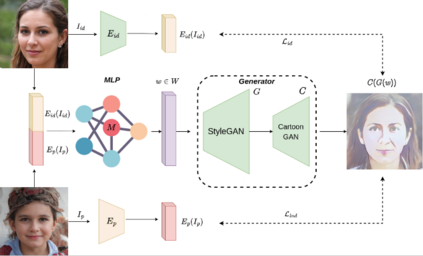
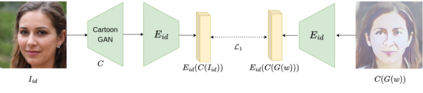
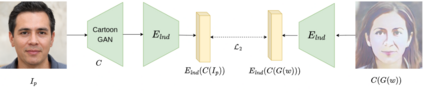
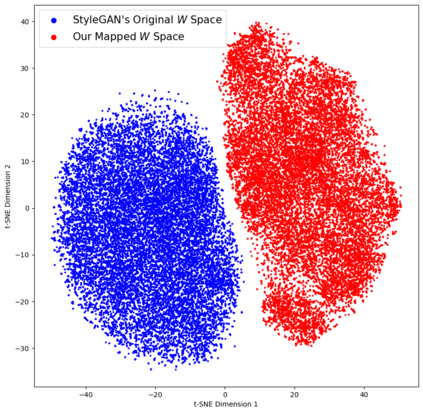
This paper presents an innovative approach to achieve face cartoonisation while preserving the original identity and accommodating various poses. Unlike previous methods in this field that relied on conditional-GANs, which posed challenges related to dataset requirements and pose training, our approach leverages the expressive latent space of StyleGAN. We achieve this by introducing an encoder that captures both pose and identity information from images and generates a corresponding embedding within the StyleGAN latent space. By subsequently passing this embedding through a pre-trained generator, we obtain the desired cartoonised output. While many other approaches based on StyleGAN necessitate a dedicated and fine-tuned StyleGAN model, our method stands out by utilizing an already-trained StyleGAN designed to produce realistic facial images. We show by extensive experimentation how our encoder adapts the StyleGAN output to better preserve identity when the objective is cartoonisation.
翻译:暂无翻译