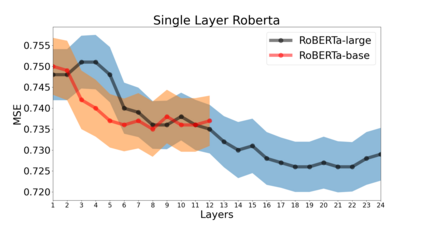
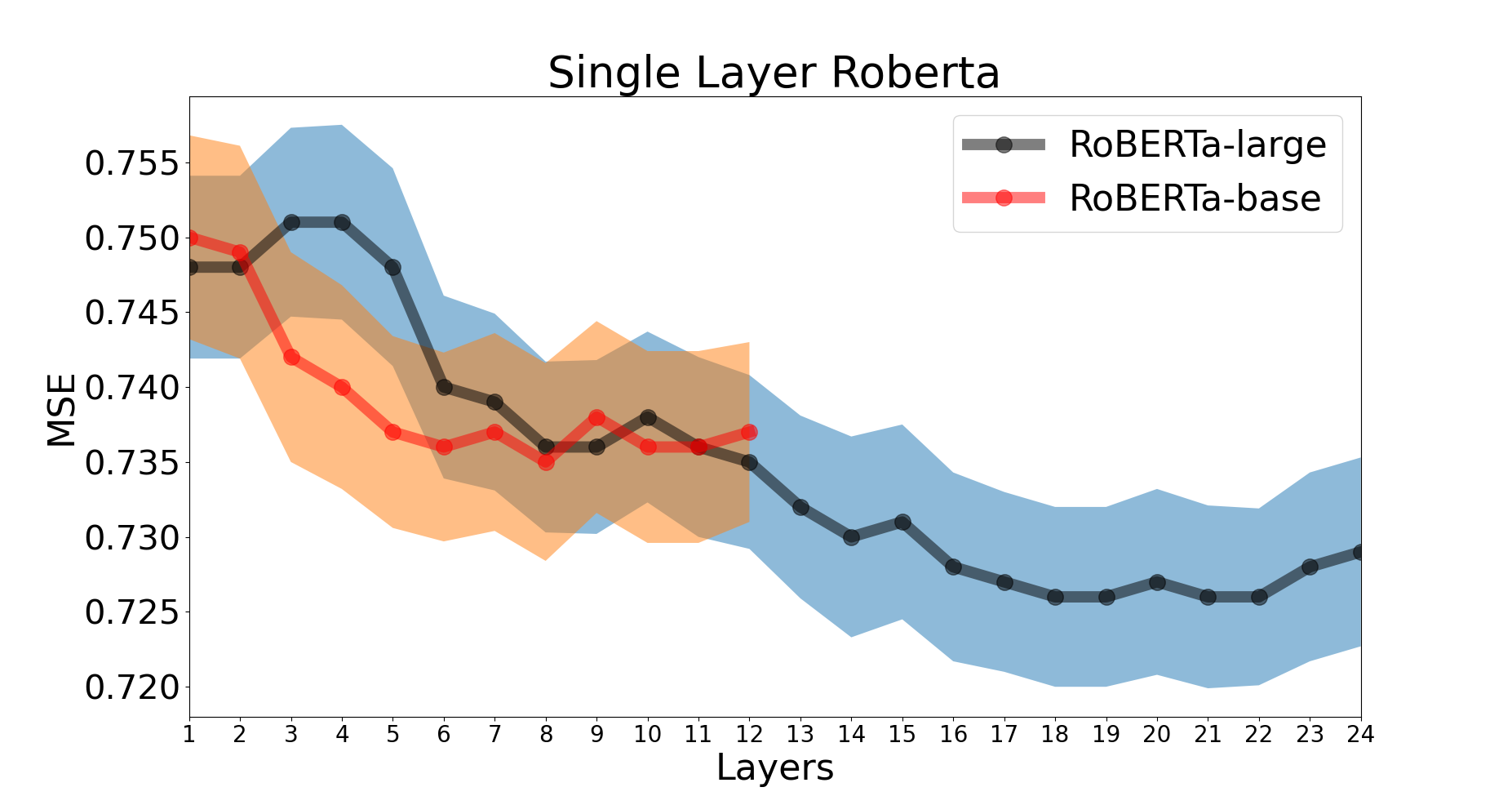
Recent works have demonstrated ability to assess aspects of mental health from personal discourse. At the same time, pre-trained contextual word embedding models have grown to dominate much of NLP but little is known empirically on how to best apply them for mental health assessment. Using degree of depression as a case study, we do an empirical analysis on which off-the-shelf language model, individual layers, and combinations of layers seem most promising when applied to human-level NLP tasks. Notably, we find RoBERTa most effective and, despite the standard in past work suggesting the second-to-last or concatenation of the last 4 layers, we find layer 19 (sixth-to last) is at least as good as layer 23 when using 1 layer. Further, when using multiple layers, distributing them across the second half (i.e. Layers 12+), rather than last 4, of the 24 layers yielded the most accurate results.
翻译:最近的工作表明有能力从个人谈话中评估心理健康的各个方面。 与此同时,预先培训的背景词嵌入模式在NLP的多数地方已经发展成为占主导地位,但对于如何最佳地应用这些模式进行心理健康评估却很少获得经验上的了解。 利用抑郁程度作为案例研究,我们做了一项经验分析,在应用到人的一级NLP任务时,哪些非现成语言模式、单个层次和各种层次组合似乎最有希望。 值得注意的是,我们认为RoBERTA最为有效,尽管过去的工作标准表明最后4个层次的第二至最后或分类,但我们发现19层(第六至最后一层)在使用1层时至少与第23层一样好。 此外,在使用多层时,将其分布在24层的第二半(即12层以上层),而不是最后4层,其结果最为准确。