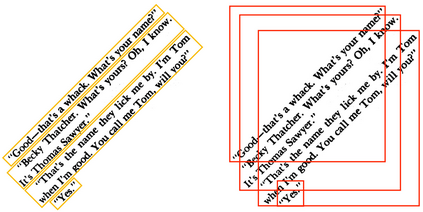
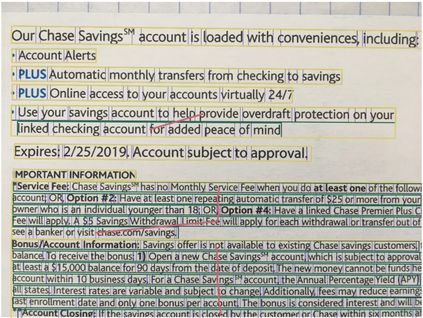
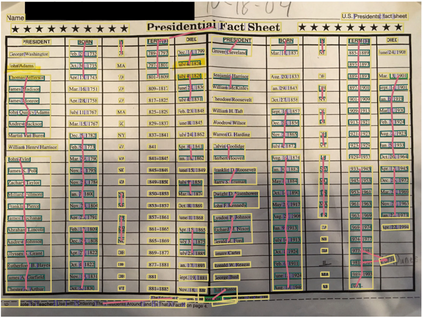
Paragraphs are an important class of document entities. We propose a new approach for paragraph identification by spatial graph convolution networks (GCN) applied on OCR text boxes. Two steps, namely line splitting and line clustering, are performed to extract paragraphs from the lines in OCR results. Each step uses a beta-skeleton graph constructed from bounding boxes, where the graph edges provide efficient support for graph convolution operations. With only pure layout input features, the GCN model size is 3~4 orders of magnitude smaller compared to R-CNN based models, while achieving comparable or better accuracies on PubLayNet and other datasets. Furthermore, the GCN models show good generalization from synthetic training data to real-world images, and good adaptivity for variable document styles.
翻译:段落是一个重要的文档实体类别。我们建议了一种新的方法,通过空间图集变异网络(GCN)在OCR文本框上应用段落识别。执行两个步骤,即线分割和线组,从OCR结果的线条中提取段落。每个步骤都使用从捆绑框中构造的β-skeleton图,图形边缘为图形变异操作提供了有效的支持。由于只有纯版面输入功能,GCN模型的大小比R-CN模型小3~4级,同时在PubLayNet和其他数据集上实现类似或更好的理解。此外,GCN模型显示了从合成培训数据到现实世界图像的良好概括,以及可变文档样式的良好适应性。