CLUENER2020:中文细粒度命名实体识别数据集来了
命名实体识别(NameEntity Recognition)是信息提取的一个子任务,其目的是将文本中的命名实体定位并分类为预定义的类别,如人员、组织、位置等。它是信息抽取、问答系统和句法分析等应用领域的重要基础技术,是结构化信息抽取的重要步骤。
目前可公开访问获得的、高质量、细粒度的中文NER数据集较少,我们(CLUE)基于清华大学开源的文本分类数据集THUCNEWS,选出部分数据进行细粒度命名实体标注,并对数据进行清洗,得到一个细粒度的NER数据集。
项目地址:
https://github.com/CLUEbenchmark/CLUENER2020
更多细节请参考我们的技术报告:
https://arxiv.org/abs/2001.04351

数据类别:
CLUENER2020共有10个不同的类别,包括:
组织(organization)
人名(name)
地址(address)
公司(company)
政府(government)
书籍(book)
游戏(game)
电影(movie)
职位(position)
景点(scene)
每个示例包含两个部分:输入的原始文本和标记的序列。原始文本是一条新闻中的一两句话;标记的序列被组织成键值对。在给定的示例中,一个类别可能会有多个实体。
数据字段解释:
以train.json为例,数据分为两列:text & label,其中text列代表文本,label列代表文本中出现的所有包含在10个类别中的实体。
例如:
text: "北京勘察设计协会副会长兼秘书长周荫如"
label: {
"organization": {
"北京勘察设计协会": [
[0, 7]
]
},
"name": {
"周荫如": [
[15, 17]
]
},
"position": {
"副会长": [
[8, 10]
],
"秘书长": [
[12, 14]
]
}
}
其中, organization, name, position代表实体类别,
"organization": {
"北京勘察设计协会": [
[0, 7]
]
}:
表示原text中, "北京勘察设计协会"
是类别为 "组织机构(organization)"
的实体, 并且start_index为0, end_index为7( 注:下标从0开始计数)
"name": {
"周荫如": [
[15, 17]
]
}:
表示原text中, "周荫如"
是类别为 "姓名(name)"
的实体, 并且start_index为15, end_index为17
"position": {
"副会长": [
[8, 10]
],
"秘书长": [
[12, 14]
]
}:
表示原text中, "副会长"是类别为 "职位(position)"的实体, 并且start_index为8, end_index为10, 同时, "秘书长"也是类别为 "职位(position)"的实体,并且start_index为12, end_index为14
标签类别定义 & 标注规则:
地址(address): **省**市**区**街**号,**路,**街道,**村等(如单独出现也标记)。地址是标记尽量完全的, 标记到最细。
书名(book): 小说,杂志,习题集,教科书,教辅,地图册,食谱,书店里能买到的一类书籍,包含电子书。
公司(company): **公司,**集团,**银行(央行,中国人民银行除外,二者属于政府机构), 如:新东方,包含新华网/中国军网等。
游戏(game): 常见的游戏,注意有一些从小说,电视剧改编的游戏,要分析具体场景到底是不是游戏。
政府(government): 包括中央行政机关和地方行政机关两级。中央行政机关有国务院、国务院组成部门(包括各部、委员会、中国人民银行和审计署)、国务院直属机构(如海关、税务、工商、环保总局等),军队等。
电影(movie): 电影,也包括拍的一些在电影院上映的纪录片,如果是根据书名改编成电影,要根据场景上下文着重区分下是电影名字还是书名。
姓名(name): 一般指人名,也包括小说里面的人物,宋江,武松,郭靖,小说里面的人物绰号:及时雨,花和尚,著名人物的别称,通过这个别称能对应到某个具体人物。
组织机构(organization): 篮球队,足球队,乐团,社团等,另外包含小说里面的帮派如:少林寺,丐帮,铁掌帮,武当,峨眉等。
职位(position): 古时候的职称:巡抚,知州,国师等。现代的总经理,记者,总裁,艺术家,收藏家等。
景点(scene): 常见旅游景点如:长沙公园,深圳动物园,海洋馆,植物园,黄河,长江等。
数据下载地址:
数据下载:
https://www.cluebenchmarks.com/introduce.html
数据分布:
训练集:10748
验证集集:1343
按照不同标签类别统计,训练集数据分布如下(注:一条数据中出现的所有实体都进行标注,如果一条数据出现两个地址(address)实体,那么统计地址(address)类别数据的时候,算两条数据):
【训练集】标签数据分布如下:
地址(address):2829
书名(book):1131
公司(company):2897
游戏(game):2325
政府(government):1797
电影(movie):1109
姓名(name):3661
组织机构(organization):3075
职位(position):3052
景点(scene):1462
【验证集】标签数据分布如下:
地址(address):364
书名(book):152
公司(company):366
游戏(game):287
政府(government):244
电影(movie):150
姓名(name):451
组织机构(organization):344
职位(position):425
景点(scene):199数据来源:
本数据是在清华大学开源的文本分类数据集THUCTC基础上,选出部分数据进行细粒度命名实体标注,原数据来源于Sina News RSS.
效果对比
CLUE组织现已完成多个基线模型的测评,相关代码传送门:
tf版本
https://github.com/CLUEbenchmark/CLUENER2020/tree/master/tf_version
pytorch版本
https://github.com/CLUEbenchmark/CLUENER2020/tree/master/pytorch_version
具体结果可在我们的排行榜(https://www.cluebenchmarks.com/introduce.html)上进行查阅。
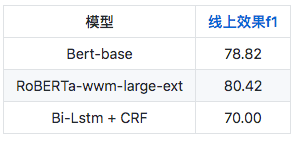
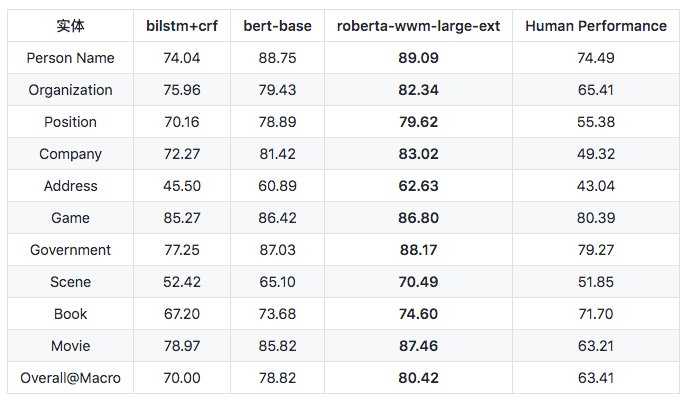
各个实体的评测结果(F1 score):
欢迎加入技术交流与问题讨论QQ群:836811304。
如果本目录中的内容对你的研究工作有所帮助,请在文献中引用下述报告:https://arxiv.org/abs/2001.04351
@article{xu2020cluener2020,
title={CLUENER2020: Fine-grained Name Entity Recognition for Chinese},
author={Xu, Liang and Dong, Qianqian and Yu, Cong and Tian, Yin and Liu, Weitang and Li, Lu and Zhang, Xuanwei},
journal={arXiv preprint arXiv:2001.04351},
year={2020}
}以下是论文全文,感兴趣的同学可以参考,点击图片可以放大阅读:





推荐阅读
中文语言理解基准测评(chineseGLUE)来了,公开征集数据集进行中
中文预训练ALBERT模型来了:小模型登顶GLUE,Base版模型小10倍速度快1倍
抛开模型,探究文本自动摘要的本质——ACL2019 论文佳作研读系列
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。





