
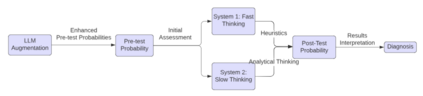
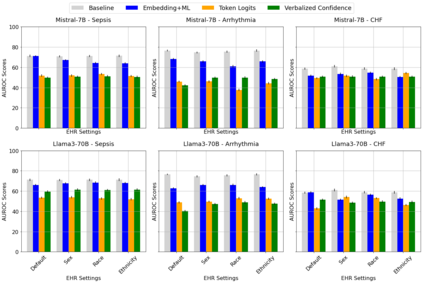
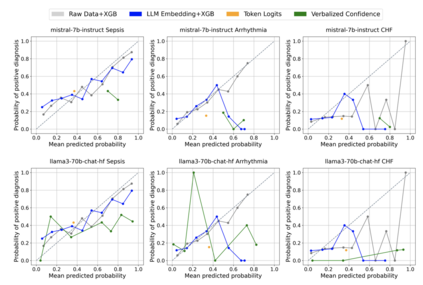
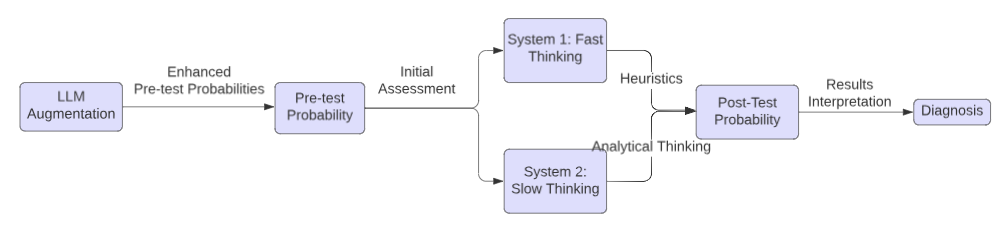
Large language models (LLMs) are being explored for diagnostic decision support, yet their ability to estimate pre-test probabilities, vital for clinical decision-making, remains limited. This study evaluates two LLMs, Mistral-7B and Llama3-70B, using structured electronic health record data on three diagnosis tasks. We examined three current methods of extracting LLM probability estimations and revealed their limitations. We aim to highlight the need for improved techniques in LLM confidence estimation.
翻译:暂无翻译

相关内容

专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
Arxiv
1+阅读 · 2024年12月20日
Arxiv
1+阅读 · 2024年12月20日
Arxiv
1+阅读 · 2024年12月20日
Arxiv
1+阅读 · 2024年12月19日
Arxiv
66+阅读 · 2023年5月31日



相关VIP内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯