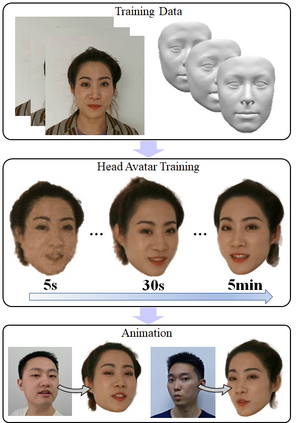
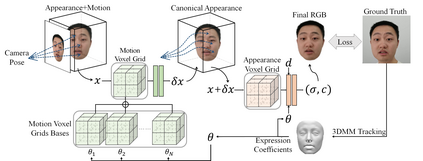
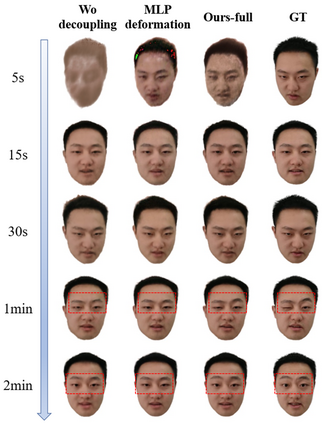
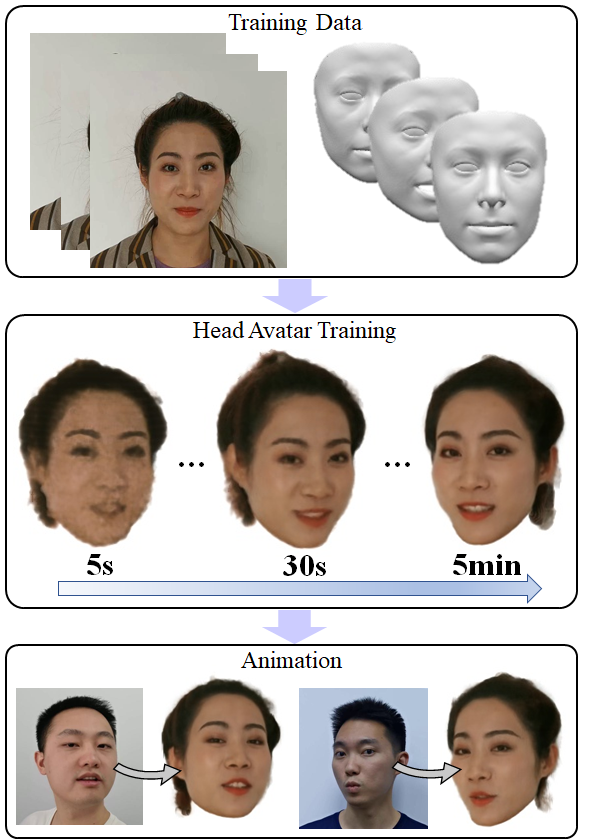
With NeRF widely used for facial reenactment, recent methods can recover photo-realistic 3D head avatar from just a monocular video. Unfortunately, the training process of the NeRF-based methods is quite time-consuming, as MLP used in the NeRF-based methods is inefficient and requires too many iterations to converge. To overcome this problem, we propose ManVatar, a fast 3D head avatar reconstruction method using Motion-Aware Neural Voxels. ManVatar is the first to decouple expression motion from canonical appearance for head avatar, and model the expression motion by neural voxels. In particular, the motion-aware neural voxels is generated from the weighted concatenation of multiple 4D tensors. The 4D tensors semantically correspond one-to-one with 3DMM expression bases and share the same weights as 3DMM expression coefficients. Benefiting from our novel representation, the proposed ManVatar can recover photo-realistic head avatars in just 5 minutes (implemented with pure PyTorch), which is significantly faster than the state-of-the-art facial reenactment methods.
翻译:面部重新反应使用NERF后,最近的方法可以从一个单视视频中恢复光现实的 3D 头电动。 不幸的是,基于 NERF 方法的培训过程非常耗时,因为 NERF 方法中使用的 MLP 效率低,需要过多的迭代才能聚合。为了解决这个问题,我们建议使用运动-软件神经氧化物的神经氧化物模型,即快速的 3D 头电动重建方法ManVatar。 ManVatar 是最先从脑血管外观中分离出光学表达动作的调和,并用神经毒气模拟表达动作。 特别是, 运动觉神经氧化物是由多四维高压的加权配制生成的。 4D 电磁共和一对一对一对应3DMM 表达基, 和3DMM 表达系数的重量相同。 从我们的新表述中得益益, 提议的ManVatar 可以在仅仅5分钟内恢复光现实头电动头( 使用纯的面膜合成法) 。 这比状态要快得多, 。