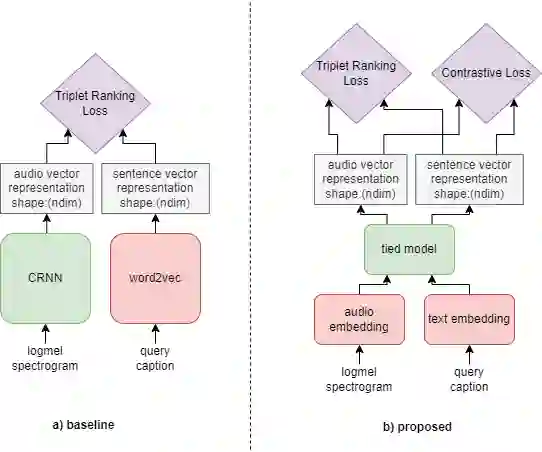
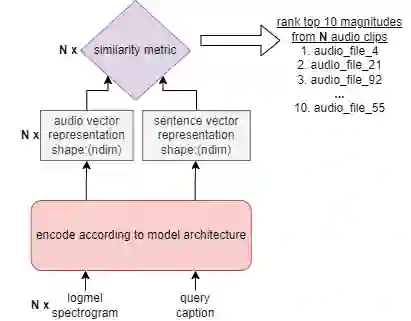
In this paper, we tackle the new Language-Based Audio Retrieval task proposed in DCASE 2022. Firstly, we introduce a simple, scalable architecture which ties both the audio and text encoder together. Secondly, we show that using this architecture along with contrastive loss allows the model to significantly beat the performance of the baseline model. Finally, in addition to having an extremely low training memory requirement, we are able to use pretrained models as it is without needing to finetune them. We test our methods and show that using a combination of our methods beats the baseline scores significantly.
翻译:在本文中,我们处理DCASE 2022 中提议的新的基于语言的音频检索任务。 首先,我们引入一个简单、可扩缩的结构,将音频和文本编码器连接在一起。 其次,我们表明,使用这一结构加上对比性损失使模型能够大大超过基线模型的性能。 最后,除了培训记忆要求极低之外,我们还能够使用预先培训的模型,因为不需要微调这些模型。我们测试了我们的方法,并表明使用我们的方法组合,大大胜过基线分数。