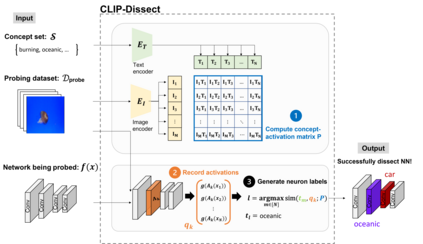
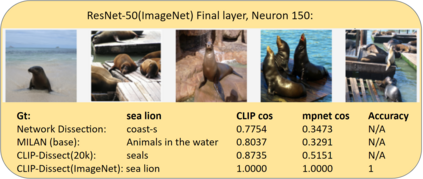
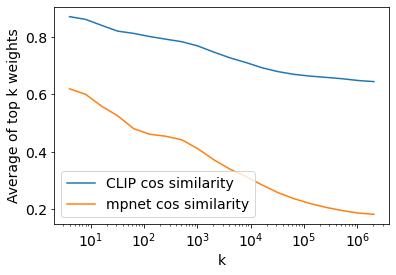
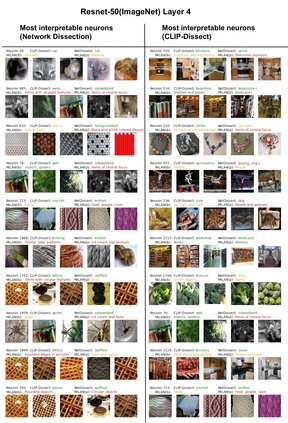
In this paper, we propose CLIP-Dissect, a new technique to automatically describe the function of individual hidden neurons inside vision networks. CLIP-Dissect leverages recent advances in multimodal vision/language models to label internal neurons with open-ended concepts without the need for any labeled data or human examples, which are required for existing tools to succeed. We show that CLIP-Dissect provides more accurate descriptions than existing methods for last layer neurons where the ground-truth is available as well as qualitatively good descriptions for hidden layer neurons. In addition, our method is very flexible: it is model agnostic, can easily handle new concepts and can be extended to take advantage of better multimodal models in the future. Finally CLIP-Dissect is computationally efficient and can label all neurons from five layers of ResNet-50 in just four minutes.
翻译:在本文中,我们提出CLIP-Discect,这是一种自动描述视觉网络内单个隐藏神经元功能的新技术。 CLIP-Discret利用多式联运愿景/语言模型的最新进展,将内部神经元贴上开放式概念的标签,而无需贴任何标签数据或人类实例,这是现有工具成功所需的。我们表明,CLIP-Discect为有地面真相的最后一个层神经元提供了比现有方法更准确的描述,并为隐藏的层神经元提供了质量良好的描述。此外,我们的方法非常灵活:它是模型的不可知性,可以很容易地处理新概念,并且可以在未来利用更好的多式联运模型。最后,CLIP-Discret是计算有效的,可以在4分钟内将ResNet-505层的所有神经元贴上标签。