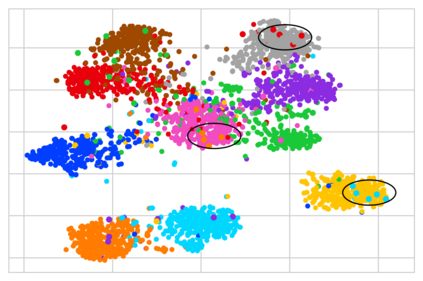
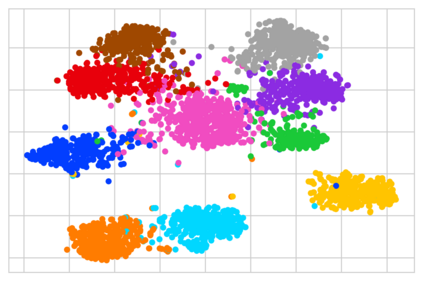
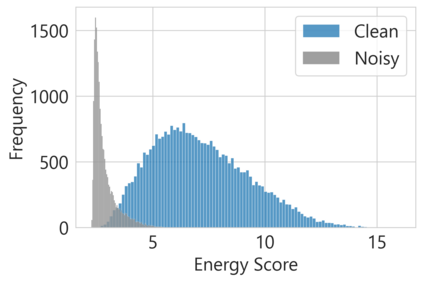
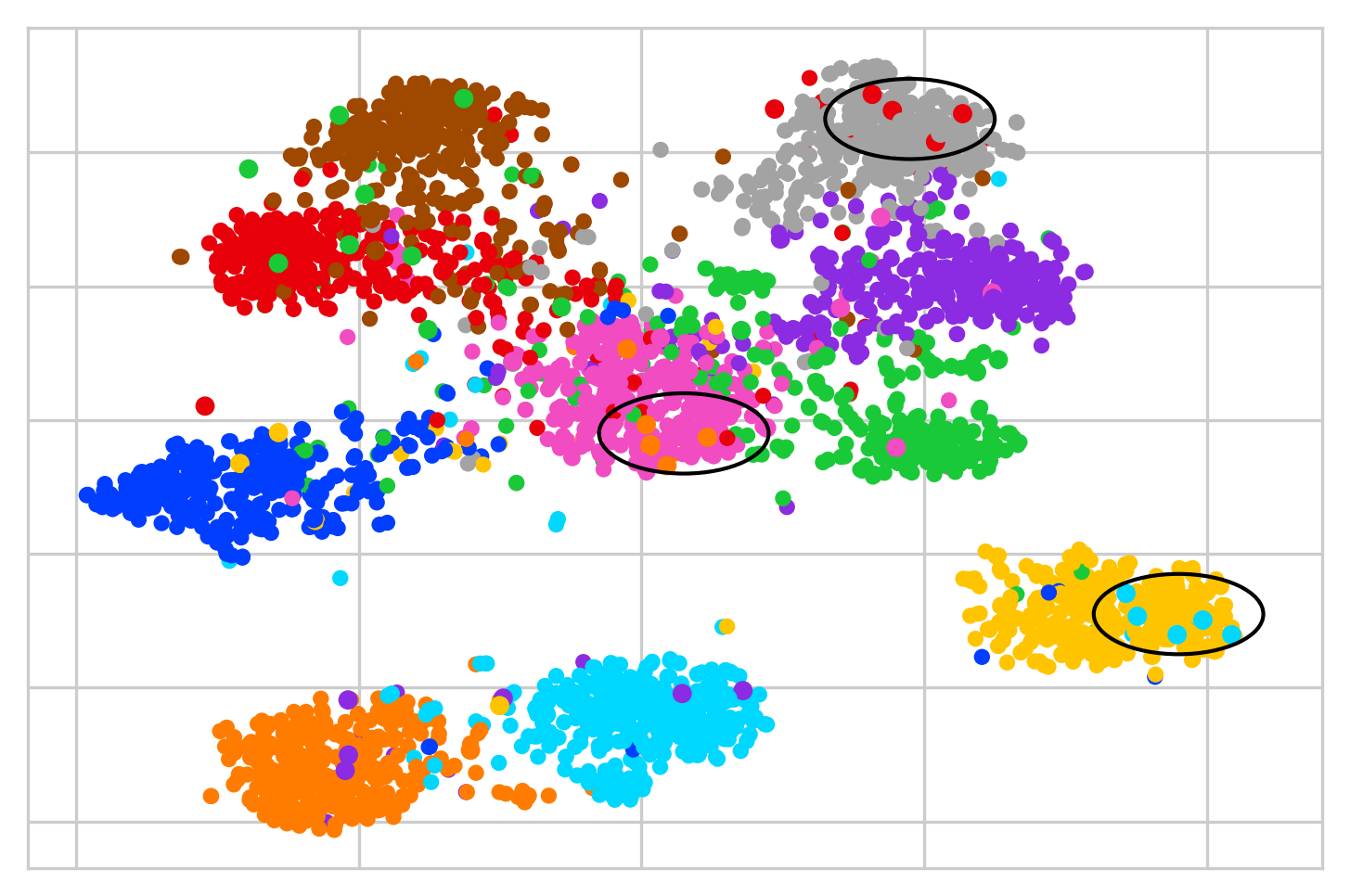
Federated Learning (FL) is a distributed machine learning paradigm that enables learning models from decentralized private datasets, where the labeling effort is entrusted to the clients. While most existing FL approaches assume high-quality labels are readily available on users' devices; in reality, label noise can naturally occur in FL and follows a non-i.i.d. distribution among clients. Due to the non-iid-ness challenges, existing state-of-the-art centralized approaches exhibit unsatisfactory performance, while previous FL studies rely on data exchange or repeated server-side aid to improve model's performance. Here, we propose FedLN, a framework to deal with label noise across different FL training stages; namely, FL initialization, on-device model training, and server model aggregation. Specifically, FedLN computes per-client noise-level estimation in a single federated round and improves the models' performance by correcting (or limiting the effect of) noisy samples. Extensive experiments on various publicly available vision and audio datasets demonstrate a 24% improvement on average compared to other existing methods for a label noise level of 70%. We further validate the efficiency of FedLN in human-annotated real-world noisy datasets and report a 9% increase on average in models' recognition rate, highlighting that FedLN can be useful for improving FL services provided to everyday users.
翻译:联邦学习联合会(FL)是一个分布式的机器学习模式,它使得从分散的私营数据集中学习模型,而标签工作则委托给客户。虽然大多数现有的FL方法假定在用户设备上很容易找到高质量的标签;在现实中,标签噪音自然会出现在FL中,并遵循非i.i.d.在客户之间分配。由于非二元性挑战,现有最先进的中央化方法表现不尽人意,而以前的FL研究依靠数据交换或反复服务器-侧援助来改进模型的性能。在这里,我们提议FLN,这是一个处理不同FL培训阶段标签噪音的框架;即FL初始化、设备模型培训以及服务器模型组合。具体地说,FLN将每个客户的噪音水平估计编成一个单圈,并通过纠正(或限制)噪音样品的效果来改进模型。关于各种公开提供的视觉和音频数据集的广泛实验表明,与现有方法相比,平均提高了24 %,用于改善70 %的标签噪音水平。我们进一步确认FDL标准,在FFD-R标准中提高了效率。