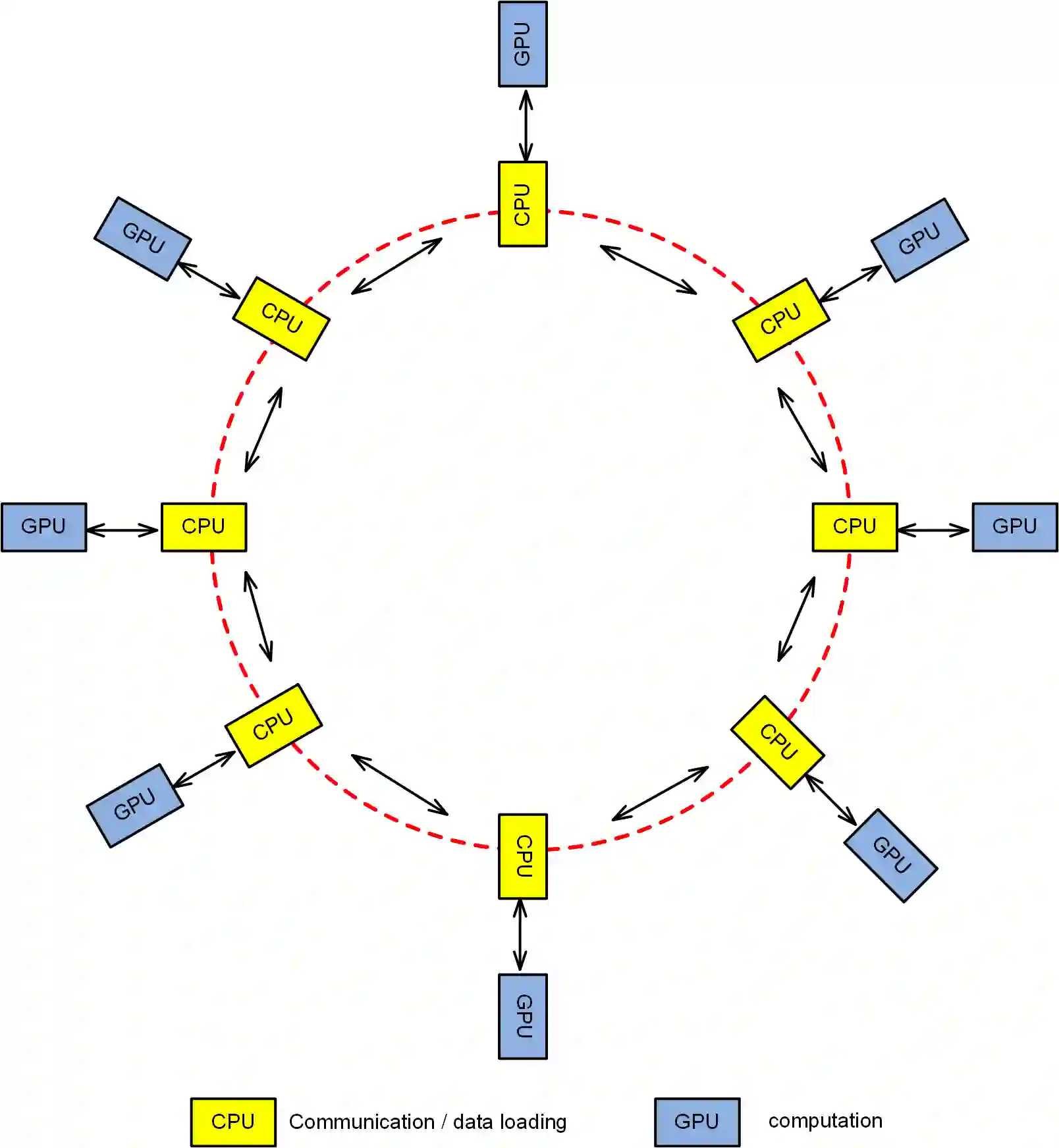
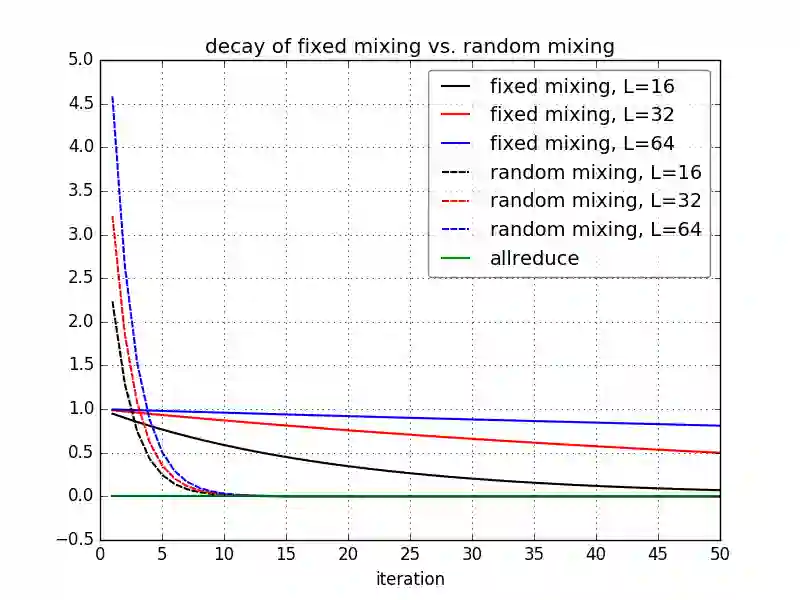
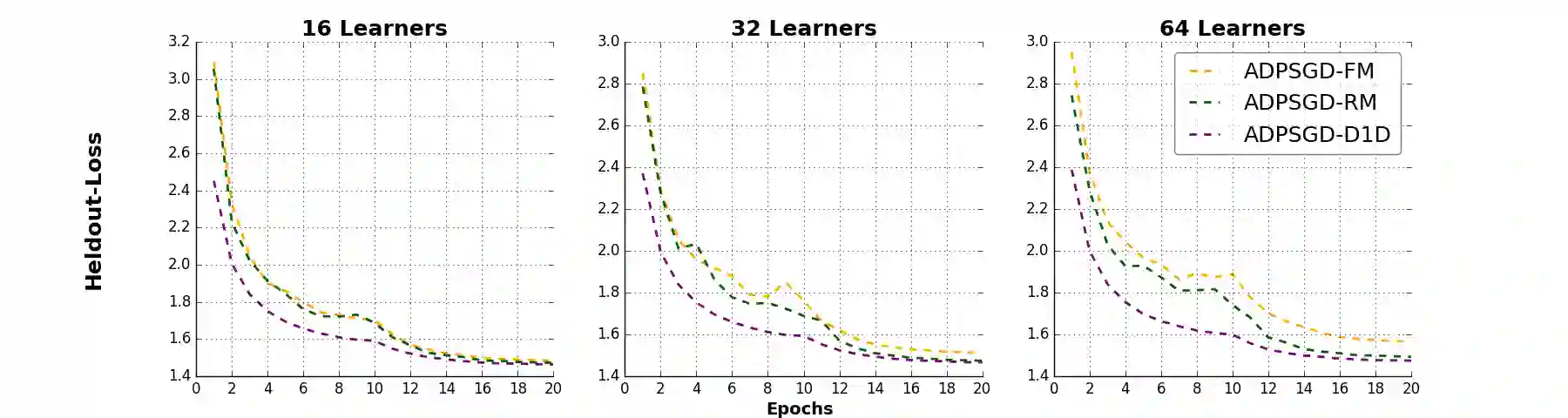
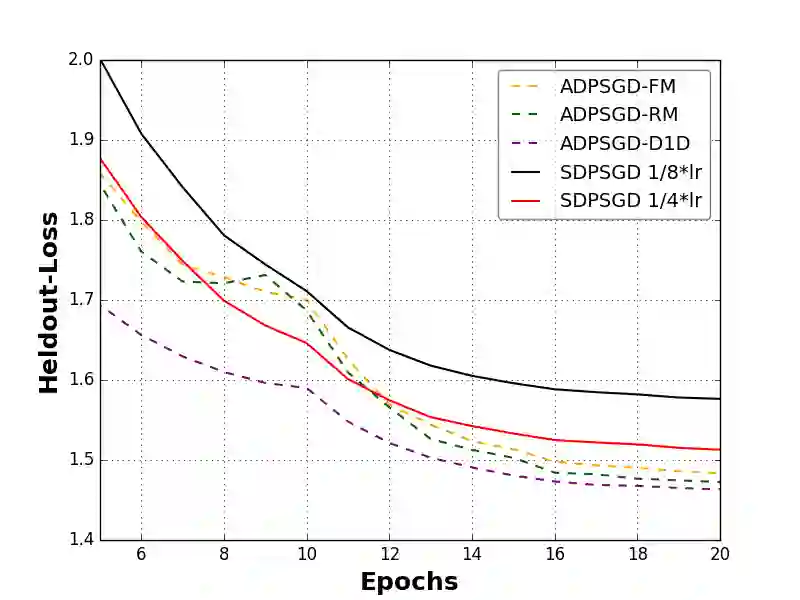
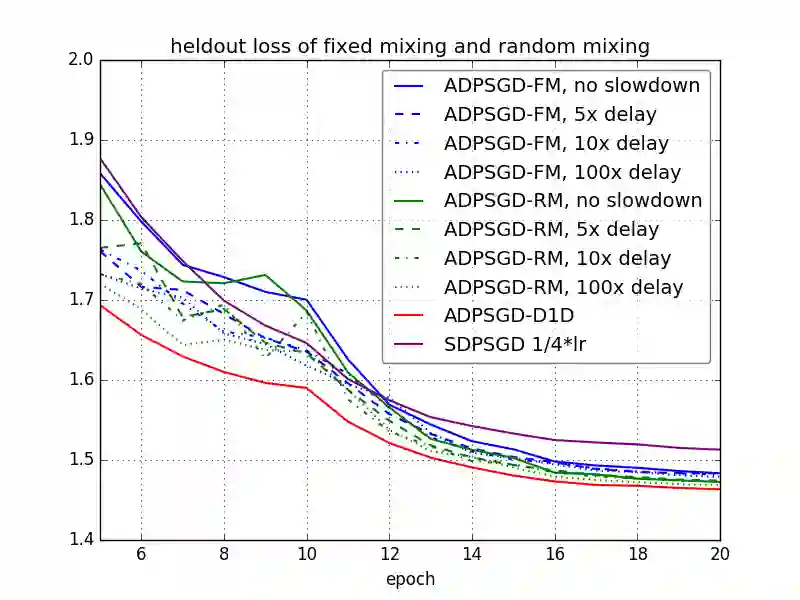
Large-scale distributed training of deep acoustic models plays an important role in today's high-performance automatic speech recognition (ASR). In this paper we investigate a variety of asynchronous decentralized distributed training strategies based on data parallel stochastic gradient descent (SGD) to show their superior performance over the commonly-used synchronous distributed training via allreduce, especially when dealing with large batch sizes. Specifically, we study three variants of asynchronous decentralized parallel SGD (ADPSGD), namely, fixed and randomized communication patterns on a ring as well as a delay-by-one scheme. We introduce a mathematical model of ADPSGD, give its theoretical convergence rate, and compare the empirical convergence behavior and straggler resilience properties of the three variants. Experiments are carried out on an IBM supercomputer for training deep long short-term memory (LSTM) acoustic models on the 2000-hour Switchboard dataset. Recognition and speedup performance of the proposed strategies are evaluated under various training configurations. We show that ADPSGD with fixed and randomized communication patterns cope well with slow learners. When learners are equally fast, ADPSGD with the delay-by-one strategy has the fastest convergence with large batches. In particular, using the delay-by-one strategy, we can train the acoustic model in less than 2 hours using 128 V100 GPUs with competitive word error rates.
翻译:对深声模型的大规模分布式培训在当今高性能自动语音识别(ASR)中发挥了重要作用。在本文件中,我们根据平行随机梯度梯度下降的数据,调查各种分散分散式培训战略,以显示其优于通过冲积(尤其是处理大批量)进行常用同步分布式培训的优异性,特别是在处理大批量时。我们研究了三种非同步分散式平行SGD(ADPSGD)的变异性,即固定和随机化的环形自动语音识别模式以及一个延迟计划。我们采用了ADPSGD的数学模型,提供其理论趋同率,并比较三个变异体的经验趋同行为和累赘弹性弹性性。实验是在IBM超级计算机上进行的,用于培训深度短时间存储(LSTM)的声学模型。在各种培训配置下,对拟议战略的承认和加速性表现进行了评估。我们发现,ADPSGDD和随机化通信模式与缓慢的学习者相匹配。当学习者使用最迅速的GPSDGD战略时,使用最慢的压速度速度可以与最慢的压。