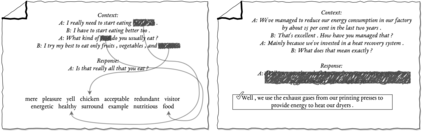
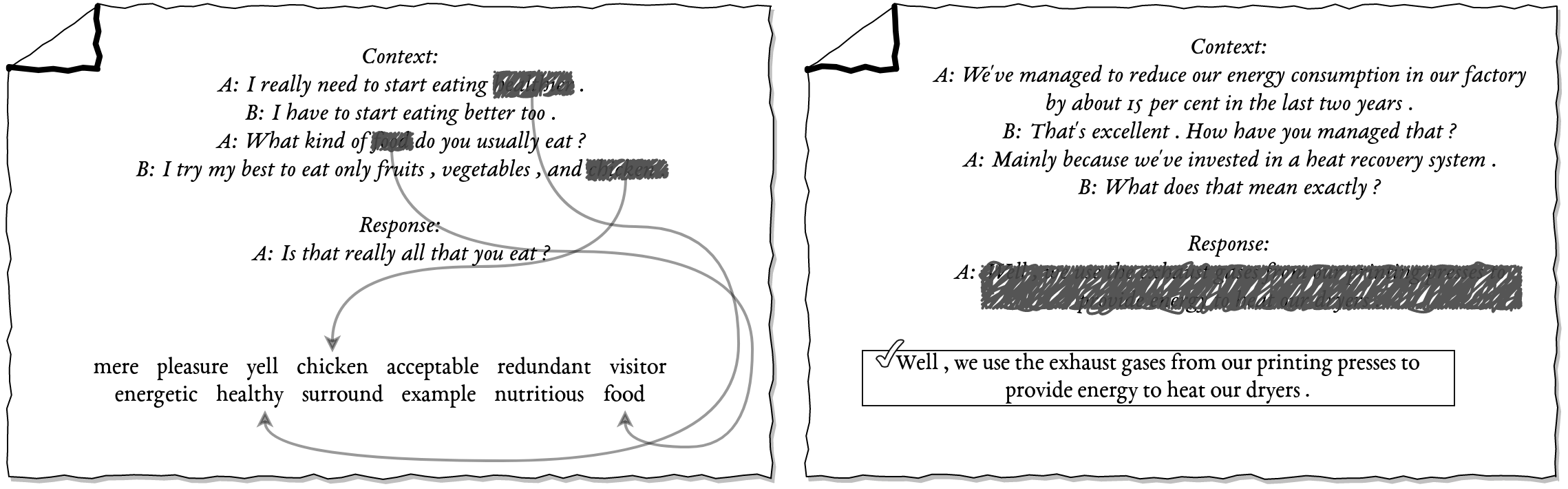
Although many pretrained models exist for text or images, there have been relatively fewer attempts to train representations specifically for dialog understanding. Prior works usually relied on finetuned representations based on generic text representation models like BERT or GPT-2. But such language modeling pretraining objectives do not take the structural information of conversational text into consideration. Although generative dialog models can learn structural features too, we argue that the structure-unaware word-by-word generation is not suitable for effective conversation modeling. We empirically demonstrate that such representations do not perform consistently across various dialog understanding tasks. Hence, we propose a structure-aware Mutual Information based loss-function DMI (Discourse Mutual Information) for training dialog-representation models, that additionally captures the inherent uncertainty in response prediction. Extensive evaluation on nine diverse dialog modeling tasks shows that our proposed DMI-based models outperform strong baselines by significant margins.
翻译:虽然存在许多文字或图像的预培训模式,但专门为对话理解而培训演示的尝试相对较少,以前的工作通常依赖基于通用文字代表模式的微调表述,如BERT或GPT-2。但是,这种语言在培训前的模拟目标中并没有考虑到谈话文字的结构信息。虽然基因化对话模式也可以学习结构特征,但我们认为,结构-无源逐字生成不适合有效的对话建模。我们从经验上证明,这种表述在各种对话理解任务中并不始终如一地发挥作用。因此,我们为对话代表模式的培训建议一种基于结构-认知的相互信息损失功能DMI( Discountly common International Information)(DMI)(DMI-Information Development DMI) (DMI) (DMIS) (Discoin-DMI) (DMI) (Discountly inter Informissional) (Derence-forence) (Dy inter im) expressive brational bractioning bration bration bration bration built.