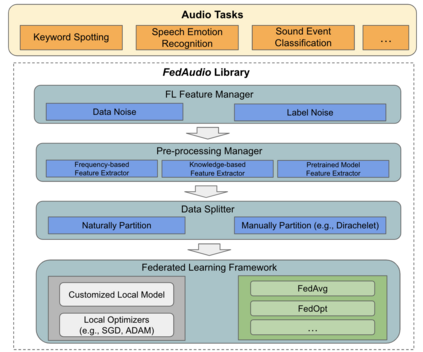
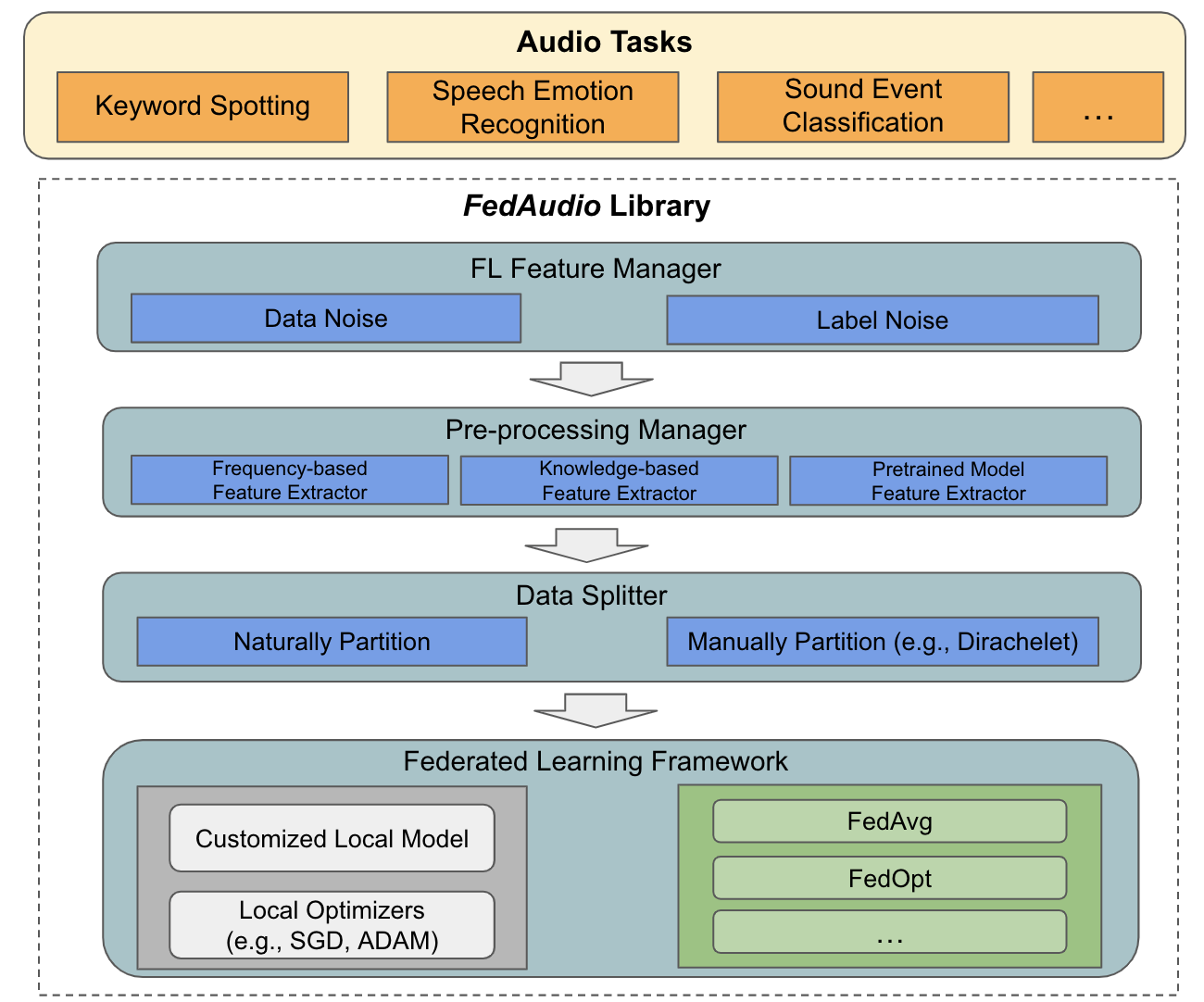
Federated learning (FL) has gained substantial attention in recent years due to the data privacy concerns related to the pervasiveness of consumer devices that continuously collect data from users. While a number of FL benchmarks have been developed to facilitate FL research, none of them include audio data and audio-related tasks. In this paper, we fill this critical gap by introducing a new FL benchmark for audio tasks which we refer to as FedAudio. FedAudio includes four representative and commonly used audio datasets from three important audio tasks that are well aligned with FL use cases. In particular, a unique contribution of FedAudio is the introduction of data noises and label errors to the datasets to emulate challenges when deploying FL systems in real-world settings. FedAudio also includes the benchmark results of the datasets and a PyTorch library with the objective of facilitating researchers to fairly compare their algorithms. We hope FedAudio could act as a catalyst to inspire new FL research for audio tasks and thus benefit the acoustic and speech research community. The datasets and benchmark results can be accessed at https://github.com/zhang-tuo-pdf/FedAudio.
翻译:近年来,联邦学习(FL)由于与不断收集用户数据的消费设备的普遍性有关的数据隐私问题而引起极大关注,近年来,联邦学习(FL)由于不断收集用户数据的消费设备的普遍性而引起数据隐私问题引起大量关注。虽然已经制定了一些FL基准,以便利FL研究,但其中没有一项包括音频数据和音频相关任务。在本文件中,我们填补了这一关键差距,为我们称为FedAudio的音频任务引入了新的FL基准。FedAudio包括了与FL使用案例完全一致的三项重要音频任务中四个具有代表性和常用的音频数据集。特别是FedAudio的独特贡献是,在数据库中引入数据噪音和标签错误,以在现实世界环境中部署FL系统时,以克服挑战。FedAudio还包含数据集和PyTorrch图书馆的基准结果,目的是便利研究人员对其算法进行公正的比较。我们希望FedAudio能够起到催化剂的作用,激发新的FLL对音频任务进行研究,从而使声频和语音研究界受益。在https://github.com/zhang-Fotoudio.