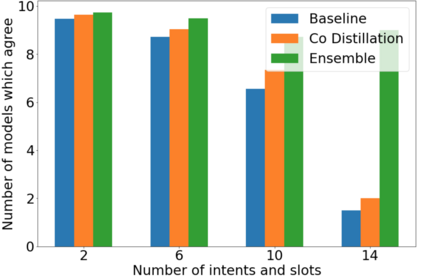
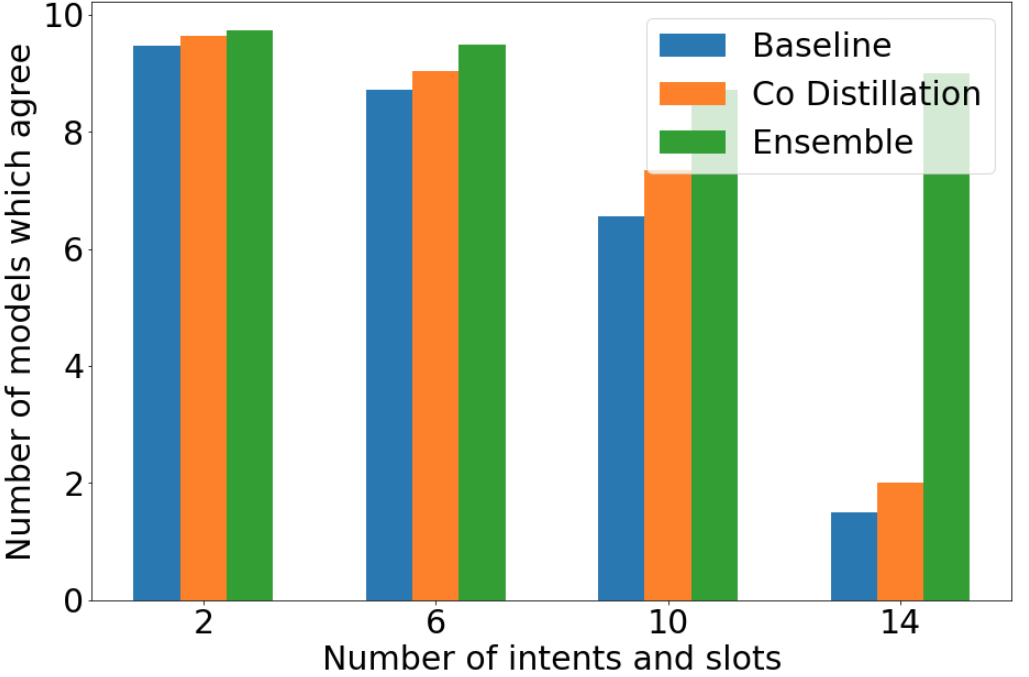
Retraining modern deep learning systems can lead to variations in model performance even when trained using the same data and hyper-parameters by simply using different random seeds. We call this phenomenon model jitter. This issue is often exacerbated in production settings, where models are retrained on noisy data. In this work we tackle the problem of stable retraining with a focus on conversational semantic parsers. We first quantify the model jitter problem by introducing the model agreement metric and showing the variation with dataset noise and model sizes. We then demonstrate the effectiveness of various jitter reduction techniques such as ensembling and distillation. Lastly, we discuss practical trade-offs between such techniques and show that co-distillation provides a sweet spot in terms of jitter reduction for semantic parsing systems with only a modest increase in resource usage.
翻译:现代深层学习系统的再培训可能导致模型性能的变化,即使经过培训使用相同的数据和超参数,只要使用不同的随机种子即可导致模型性能的变化。我们称这种现象为模型紧张状态。在生产环境中,这一问题往往会更加严重,因为模型根据吵闹的数据进行再培训。在这项工作中,我们处理稳定再培训的问题,重点是谈话语义解析器。我们首先通过采用示范协议衡量标准来量化模型性能紧张状态问题,并显示数据集噪音和模型大小的变异。我们随后展示了各种减少弹道技术(例如编组和蒸馏)的功效。最后,我们讨论了这些技术之间的实际权衡,并表明共同蒸馏为语义解析系统提供了一个精密的裁量点,只有少量的资源使用量。