25篇AAAI 2018接收论文在哈工大直播预讲,顶会预先看!
AI 科技评论按:1月6日,由中国计算机学会青年工作者协会(简称「青工委」)举办的『AAAI 2018 预讲会』在哈尔滨工业大学举办。在一天的议程中,共有来自全国各地15所高校和研究单位的老师和同学分享他们在AAAI 2018中接收的论文(共25篇)。
预讲会开始后,青工委主任、清华大学刘洋教授介绍了青工委的整体情况,并指出青工委在接下来一年中的学术活动计划:

本篇预讲会25篇论文按照报告先后分别为:
1\Adversarial Learning for Chinese NER from Crowd Annotations(张梅山,苏州大学)
2\Adaptive Co-attention Network for Named Entity Recognition in Tweets(傅金兰,复旦)
3\Large Scaled Relation Extraction with Reinforcement Learning(陈玉博「代」,自动化所)
4\Event Detection via Gated Multilingual Attention Mechanism(陈玉博,自动化所)
5\Neural Networks Incorporating Dictionaries for Chinese Word Segmentation(刘晓雨,复旦)
6\Learning Multimodal Word Representation via Dynamic Fusion Methods(王少楠,自动化所)
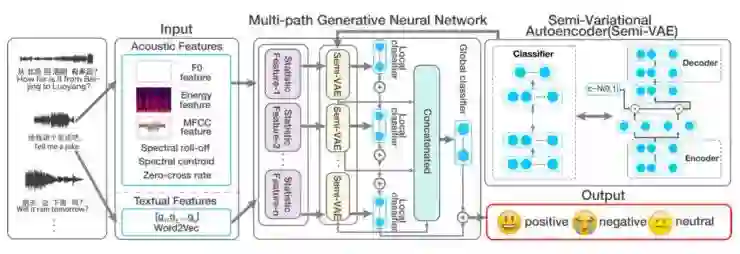
7\Inferring Emotion from Conversational Voice Data: A Semi-supervised Multi-path Generative Neural Network Approach(周素平,清华)
8\Long Text Generation via Adversarial Training with Leaked Information(郭家贤,上交大)
9\Style Transfer in Text: Exploration and Evaluation(付振新,北大)
10\Meta Multi-Task Learning for Sequence Modeling(陈俊坤,复旦)
11\RUBER: An Unsupervised Method for Automatic Evaluation of Open-Domain Dialog Systems(严睿,北大)
12\Exploring Implicit Feedback for Open Domain Conversation Generation(张伟男,哈工大)
13\Neural Character-level Dependency Parsing for Chinese(赵海,上交大)
14\A Neural Transition-Based Approach for Semantic Dependency Graph Parsing(王宇轩,哈工大)
15\Asynchronous Bidirectional Decoding for Neural Machine Translation(张祥文,厦大)
16\Knowledge Graph Embedding with Iterative Guidance from Soft Rules(王泉,信工所)
17\Embedding of Hierarchically Typed Knowledge Bases(孔繁爽,北航)
18\Faithful to the Original: Fact-Aware Neural Abstractive Summarization(曹自强,香港理工)
19\Twitter Summarization based on Social Network and Sparse Reconstruction(何瑞芳,天津大学)
20\ Improving Review Representations with User Attention and Product Attention for Sentiment Classification(吴震,南京大学)
22\Learning Structured Representation for Text Classification via Reinforcement Learning(杨成,清华)
23\Assertion-based QA with Question-Aware Open Information Extraction(杨成「代」,清华)
24\End-to-End quantum language model with Application to Question Answering(冯骁骋「代」,哈工大)
25\EMD Metric Learning(张子昭,清华)
下面AI科技评论将对部分论文做简要介绍,感兴趣的同学可以下载原论文进行阅读和研究。
2\Adaptive Co-attention Network for Named Entity Recognition in Tweets
报告人:傅金兰(复旦)
在tweet的命名实体识别任务中,传统的方法往往只使用了文本处理,这种方法有时会出现错误。这篇论文的作者提出将文本和图片结合起来共同来识别命名实体,也即在文本识别模型中加入图像识别模块。
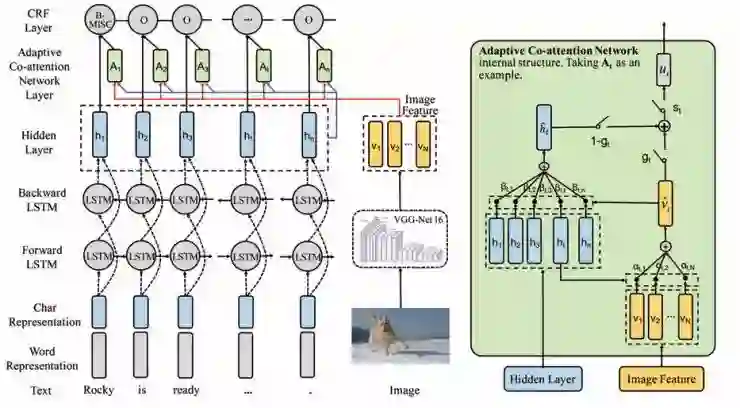
但是文章的实验结果表明性能上似乎并不没有很大的提升,原因可能是文本方法的命名实体识别错误率并不是很多。
3\Large Scaled Relation Extraction with Reinforcement Learning
报告人:陈玉博(自动化所)
从文本中进行关系抽取在NLP领域是一个重要的任务。目前主要有两种方法:句子级的关系抽取和基于知识库的bag级关系抽取。前者需要有人工标注,难以大规模应用;后者虽然能够大规模进行关系抽取,但是它只有bag的label,而没有具体句子的label。作者使用增强学习的方法,将包中的句子看成增强学习的state,将关系看成action,将关系抽取分类器看成agent,从而构建了一个能够依据大规模自动回标的包数据训练出一个高质量的句子级的关系抽取的分类器。
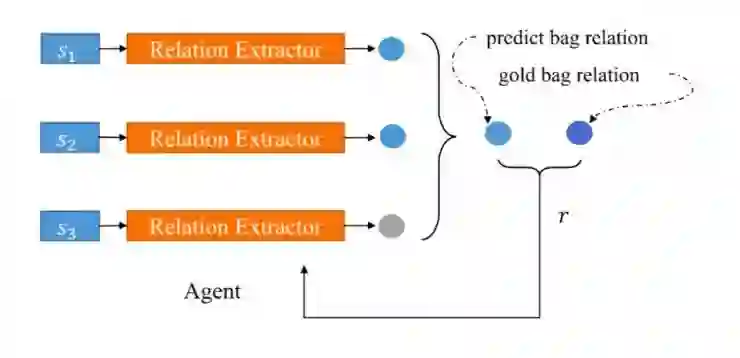
基于这种方法构建的两个模型,在实验中相比CNN和PE方法有19.71%和13.36%的显著提升。
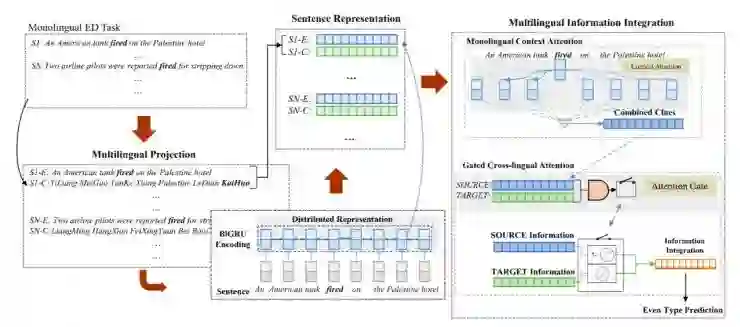
4\Event Detection via Gated Multilingual Attention Mechanism
报告人:陈玉博(自动化所)
在NLP应用(例如信息提取系统)中,如何从文本中识别出事件非常重要。现存方法主要根据单一一种语言来做,这些方法会受困于语言自身的歧义性以及数据不足的影响。本文提出了一种利用双语(多语)之间一致性事件和其他丰富的信息构建的Gated MultiLingual Attention (GMLATT) 框架来试图消除前面两种影响。
5\Neural Networks Incorporating Dictionaries for Chinese Word Segmentation
报告人:刘晓雨(复旦大学)
近年来深度神经网络在中文分词领域取得了很大的成功,但目前这种类型的方法在处理低频词汇和领域专有名词时的表现并不是很好。这篇论文提出一种结合词典的神经网络方法,利用人类知识来提升神经网络在分词任务中的表现。
实验结果表明,这种方法在在大多数领域文本的分词中表现比state-of-art方法更好,在多领域的文本分词中相对state-of-art方法有显著提升。
6\Learning Multimodal Word Representation via Dynamic Fusion Methods
在学习语义词汇表示任务中,多模态模型要比单纯的基于文本的模型表现要好。之前所有的多模态模型在学习过程中会将不同模态的重要性视为相同,但我们知道不同类型的词汇在表示学习时对文字、图片或者声音的依赖程度是不一样的,所以应该给它们赋予不同的权重。本文提出了一种对不同模态进行动态赋权的方法。
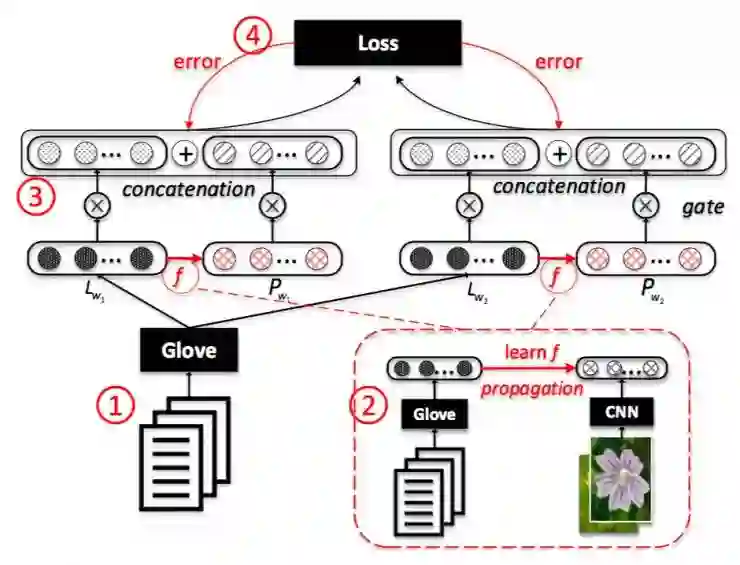
7\Inferring Emotion from Conversational Voice Data: A Semi-supervised Multi-path Generative Neural Network Approach
报告人:周素平(清华大学)
为了在语音对话应用(VDAs)中给出更人性化的回应,识别用户询问的情绪是一个重要的任务。在VDAs中,我们有大量的未标记的数据,这些数据用高维特征来表示其多模态信息。在这篇论文中,作者提出了一种半监督、多路径的生成神经网络。
实验的结果相对state-of-the-art 结果又显著提升。
8\Long Text Generation via Adversarial Training with Leaked Information
报告人:郭家贤(上海交通大学)
在长文本生成中,现有的模型(GAN方法)的标量引导信号只有在文本完整生成后才可以使用,并且在生成过程中缺少关于文本结构的中间信息,这些因素会限制长文本生成结果的效果。
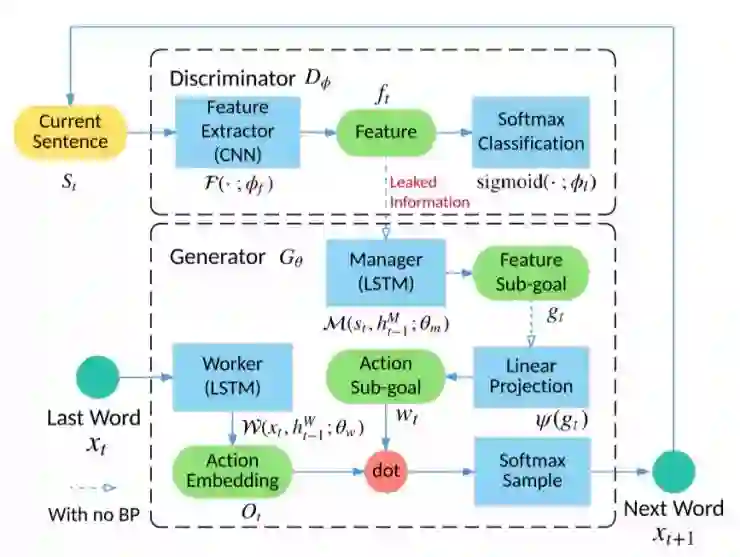
本文提出了一种名为LeakGAN的框架,也即在生成的过程中判断网会将提取的特征“泄露”给生成网络。这个模型来源于一种想法,即人在说一句较长的话时,不是一下子把所有的词都想完整了再说,而是在说的过程中不断根据前面内容生成接下来要说的话。
其实验证明,LeakGAN在长文本生成中非常有效,并且在短文本生成场景中也提高了性能。
9\Style Transfer in Text: Exploration and Evaluation
报告人:付振新(北大计算科学与技术研究所)
这份文章的工作属于探索性的工作,作者尝试构建一种无平行语料数据集的风格转换生成方法,并提出相应的评价指标。
工作思路如图所示:

两种评价指标分别为:Transfer Strength(是否有风格迁移)和Content Preservation(评估源和目标模型之间内容的相似性)。
11\RUBER: An Unsupervised Method for Automatic Evaluation of Open-Domain Dialog Systems
报告人:严睿(北京大学计算科学与技术研究所)
开放域对话系统目前还不存在标准的自动评估指标。 研究者通常会使用人工标注进行模型评估,但这种方法费时费力。在这篇文章中,作者提出了一种referenced 度量和Unreferenced 度量混合评估的RUBER,它通过同时考虑一个ground truth答复和一个查询(先前用户发出的话语)来评估一个答案。 这种指标是可以学习的,它的训练并不需要人类满意的标签。 所以RUBER比较灵活,可以扩展到不同的数据集和语言上。 在对检索和生成对话系统的实验表明,RUBER与人类标注有很高的相关性。
12\Exploring Implicit Feedback for Open Domain Conversation Generation
报告人:张伟男(哈尔滨工业大学)
在人机对话过程中,人们通常会表现出某种立场、情绪以及尴尬等状态,我们称之为用户在人机对话过程中的隐式反馈。相比于任务型人机对话在对话结束后通过问卷的形式显式地获取用户的反馈,隐式反馈更加自然且不需要用户作出对话之外的反馈操作。在开放域人机对话中,用户的隐式反馈普遍存在,因此本文将探寻人机对话过程中的用户隐式反馈对于开放域对话生成的作用,在强化学习的框架下,将隐式反馈建模到对话奖励函数中,获得比baseline更好的对话生成效果。
14\A Neural Transition-Based Approach for Semantic Dependency Graph Parsing
语义依存图是近年来提出的对树结构句法或语义表示的扩展,它与树结构的主要区别是允许一些词拥有多个父节点,从而使其成为有向无环图(directed acyclic graph,DAG)。因此要获得句子的语义依存图,就需要对这种DAG进行分析。目前大多数工作集中于研究浅层依存树结构,少有人研究如何对DAG进行分析。本文提出一种基于转移的分析器,使用list-based arc-eager算法的变体对依存图进行分析。
15\Asynchronous Bidirectional Decoding for Neural Machine Translation
报告人:张祥文(厦门大学)
传统的机器翻译中都是按照单向顺序编码。这种方法的一个缺点就是,一旦中间出现翻译错误,随后的内容就会出现很大的差错。本文作者提出了一种双向编码的新思路。
实验结果相较之前的方法有显著提升。但是这种效果的提升是以消耗计算量为代价的。
16\Knowledge Graph Embedding with Iterative Guidance from Soft Rules
报告人:王泉(信息工程研究所)
将知识图谱嵌入连续向量空间是当前研究的重点。最近,将这种模型与逻辑规则相结合引起了越来越多的关注。但是以往的大多数尝试都是一次性注入逻辑规则,而忽略了嵌入式学习和逻辑推理之间的交互性。而且他们只专注于硬性规则,这些规则始终保持不变,通常需要大量的手动工作来创建或验证。本文作者提出了一种新的KG嵌入的范式——规则引导嵌入(RUGE),用软规则的迭代引导。 通过这个迭代过程,逻辑规则中体现的知识可以更好地转移到学习的嵌入中。
18\Faithful to the Original: Fact-Aware Neural Abstractive Summarization
报告人:曹自强(香港理工大学)
与抽取摘要不同,生成式摘要在融合原文本的过程中往往会创造出虚假的事实。目前有近30%的最先进的神经系统都会受到这种问题的困扰。以前生成式摘要主要着眼于信息性的提高,作者认为忠实性(也即“信”)是生成摘要的前提,非常重要。
为了避免在生成摘要中产生虚假事实,作者使用了开放的信息抽取和依存分析技术从源文本中提取实际的事实描述,然后提出dual-attention sequence-to-sequence框架来强制以原文本和提取的事实描述为条件的生成。实验表明,他们的方法可以减少80%的虚假事实。
21\Chinese LIWC Lexicon Expansion via Hierarchical Classification of Word Embeddings with Sememe Attention
报告人:杨成(清华)
语言查询和字数统计(LIWC)是一个字数统计软件工具,已被用于许多领域的定量文本分析。由于其成功和普及,核心词汇已被翻译成中文和许多其他语言。然而,词汇只包含数千个单词,与汉语常用单词的数量相比是不足的。目前的方法通常需要手动扩展词典,但是这往往需要太多时间,需要语言专家来扩展词典。为了解决这个问题,作者建议自动扩展LIWC词典。具体而言,作者认为它是一个层次分类问题,并利用序列到序列模型来分类词典中的单词。而且,作者使用关注机制的义位信息来捕捉一个词的确切含义,以便可以扩展一个更精确、更全面的词汇。
22/Learning Structured Representation for Text Classification via Reinforcement Learning
报告人:杨成「代」(清华大学)
表征学习是自然语言处理中的一个基本问题。本文研究如何学习文本分类的结构化表示。与大多数既不使用结构也不依赖于预定义结构的现有表示模型不同,作者提出了一种强化学习(RL)方法,通过自动地优化结构来学习句子表示。
结果表明,这种方法可以通过识别重要的词或任务相关的结构而无需明确的结构注释来学习任务友好的表示,从而获得有竞争力的表现。
24/End-to-End quantum language model with Application to Question Answering
报告人:苏展(天津大学)
语言建模(LM)是一系列领域的基础研究课题。 最近,在量子理论的启发下已经有人提出了一种新的量子语言模型(QLM)用于信息检索(IR)。 作者在本文中开发了一个基于神经网络的类量子语言模型(N-NQLM),并将其应用于问题回答。
以上内容仅供参考,详细信息请查看原论文。
本次会议由中文信息学会青工委主办,哈工大SCIR承办,赞助商有华为和云孚科技。雷锋网作为唯一合作媒体,提供了在线直播,并对本次预讲会做全程报道。
————— 新人福利 —————
关注AI 科技评论,回复 1 获取
【数百 G 神经网络 / AI / 大数据资源,教程,论文】
————— AI 科技评论招人了 —————
AI 科技评论期待你的加入,和我们一起见证未来!
现诚招学术编辑、学术兼职、学术外翻
详情请点击招聘启事
————— 给爱学习的你的福利 —————
AI慕课年度学习盛典
爆款课程限时打折,优惠卡券免费领取
精品课程1元秒杀,买课即送热门图书
点击阅读原文,即刻获取优惠
▼▼▼

————————————————————





