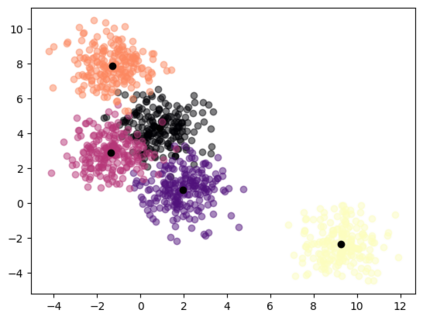
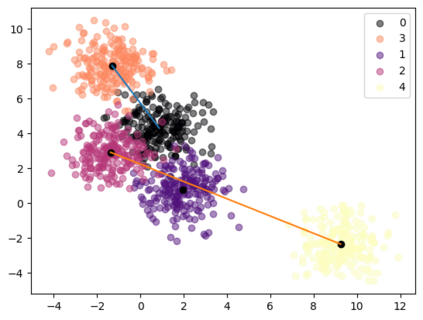
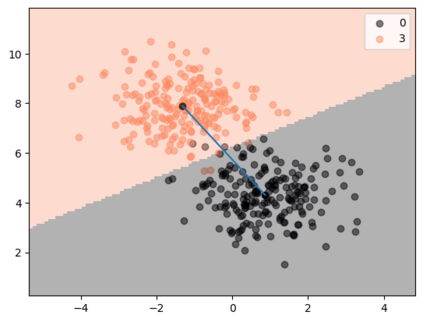
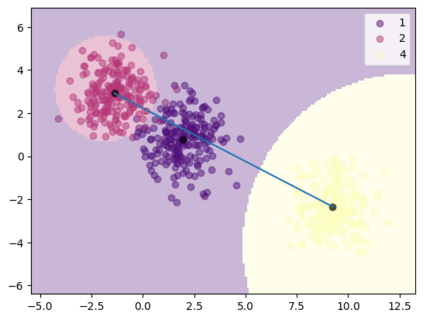
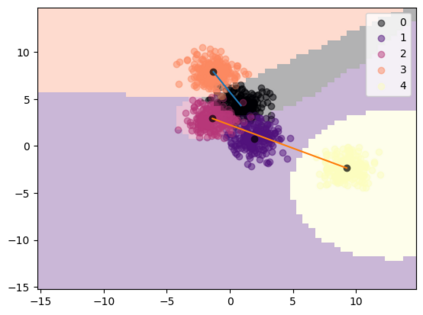
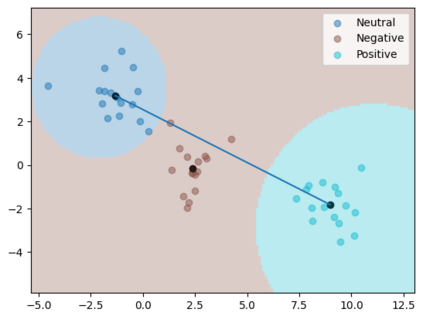
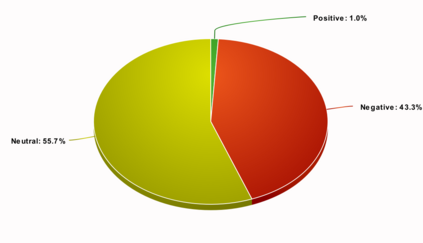
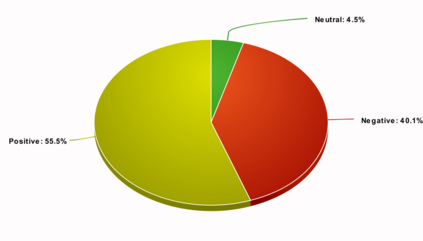
It has been experimentally demonstrated that humans are able to learn in a manner that allows them to make predictions on categories for which they have not seen any examples (Malaviya et al., 2022). Sucholutsky and Schonlau (2020) have recently presented a machine learning approach that aims to do the same. They utilise synthetically generated data and demonstrate that it is possible to achieve sub-linear scaling and develop models that can learn to recognise N classes from M training samples where M is less than N - aka less-than-one shot learning. Their method was, however, defined for univariate or simple multivariate data (Sucholutsky et al., 2021). We extend it to work on large, high-dimensional and real-world datasets and empirically validate it in this new and challenging setting. We apply this method to learn previously unseen NLP tasks from very few examples (4, 8 or 16). We first generate compact, sophisticated less-than-one shot representations called soft-label prototypes which are fitted on training data, capturing the distribution of different classes across the input domain space. We then use a modified k-Nearest Neighbours classifier to demonstrate that soft-label prototypes can classify data competitively, even outperforming much more computationally complex few-shot learning methods.
翻译:实验性地证明,人类能够以能够对其没有看到的任何实例(Malaviya等人,2022年,2022年)的类别作出预测的方式学习,Sucholutsky和Schonlau(202020年)最近提出了一种旨在这样做的机器学习方法。他们利用合成产生的数据,并表明有可能实现亚线缩放和开发模型,以便从M类培训样本中识别N类,而M类比N小于N-aka少于一镜头的学习。但是,他们的方法是为单项或简单的多变量数据(Sucholutsky等人,2021年)界定的。我们将其推广到大型、高维和真实世界数据集上,并在这种新的和具有挑战性的环境中对它进行实验性验证。我们用这种方法从极少数例子(4、8或16)中学习以前不为人见的NLP任务。我们首先产生紧凑的、精密的比不一镜头演示,称为软标签原型的模型,用于培训数据,捕捉到不同输入域空间的教室分布(Sucollutly kearal-stalstal assal),然后我们随后用了一个更具有的Kearal-ch的模型,甚至可以将一个更具有竞争力的Keargillingingingingingingdalmax