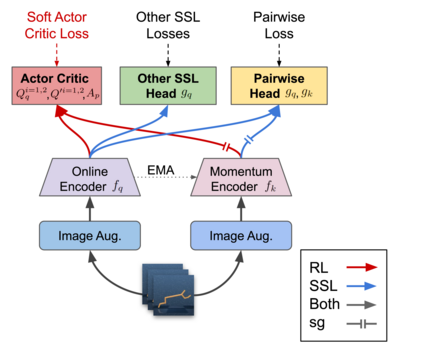
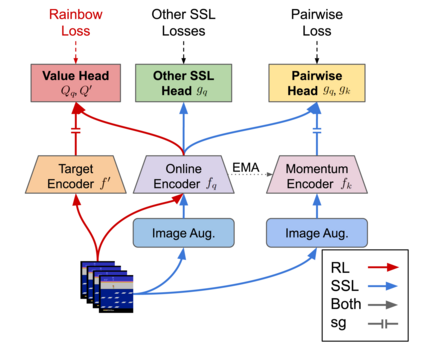
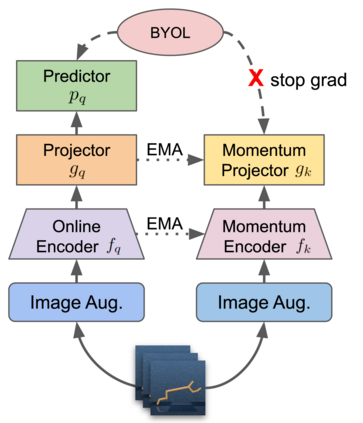
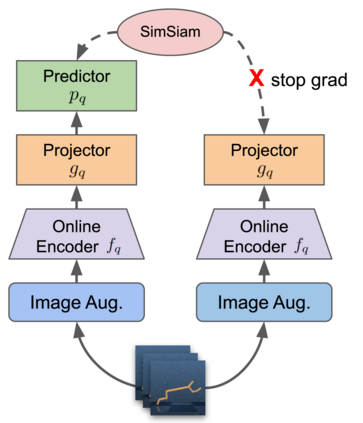
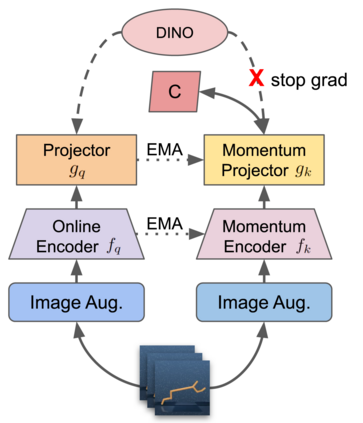
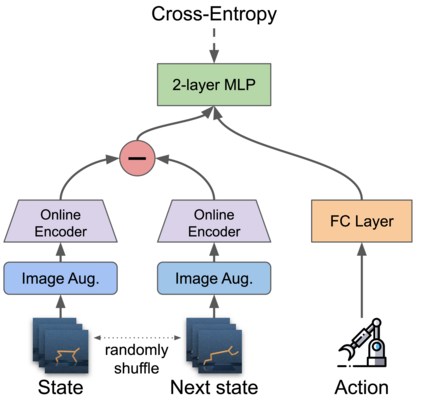
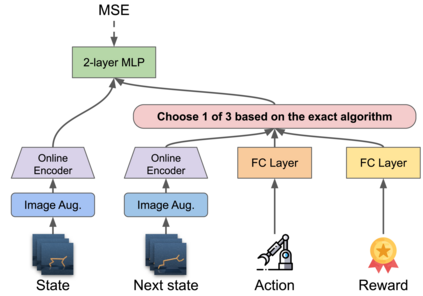
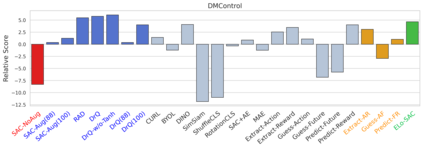
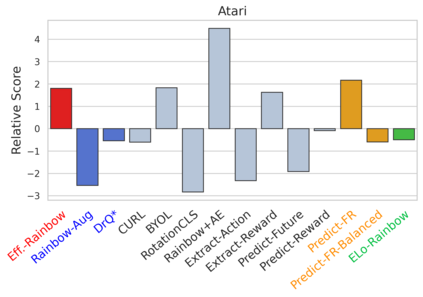
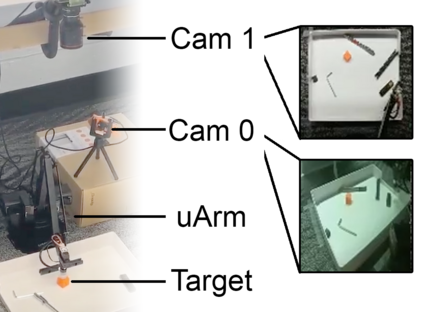
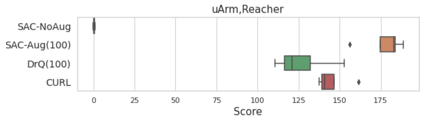
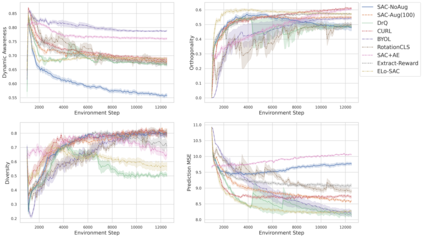
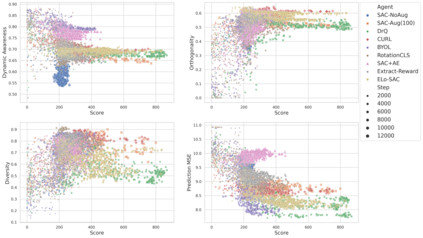
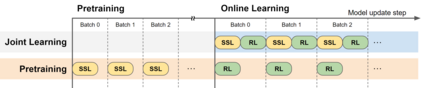
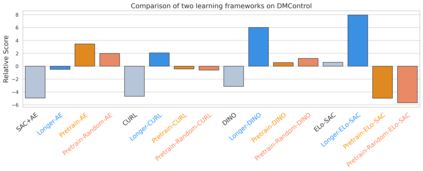
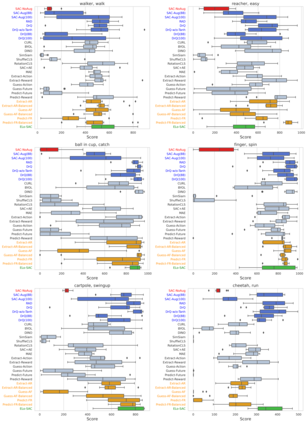
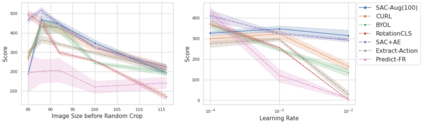
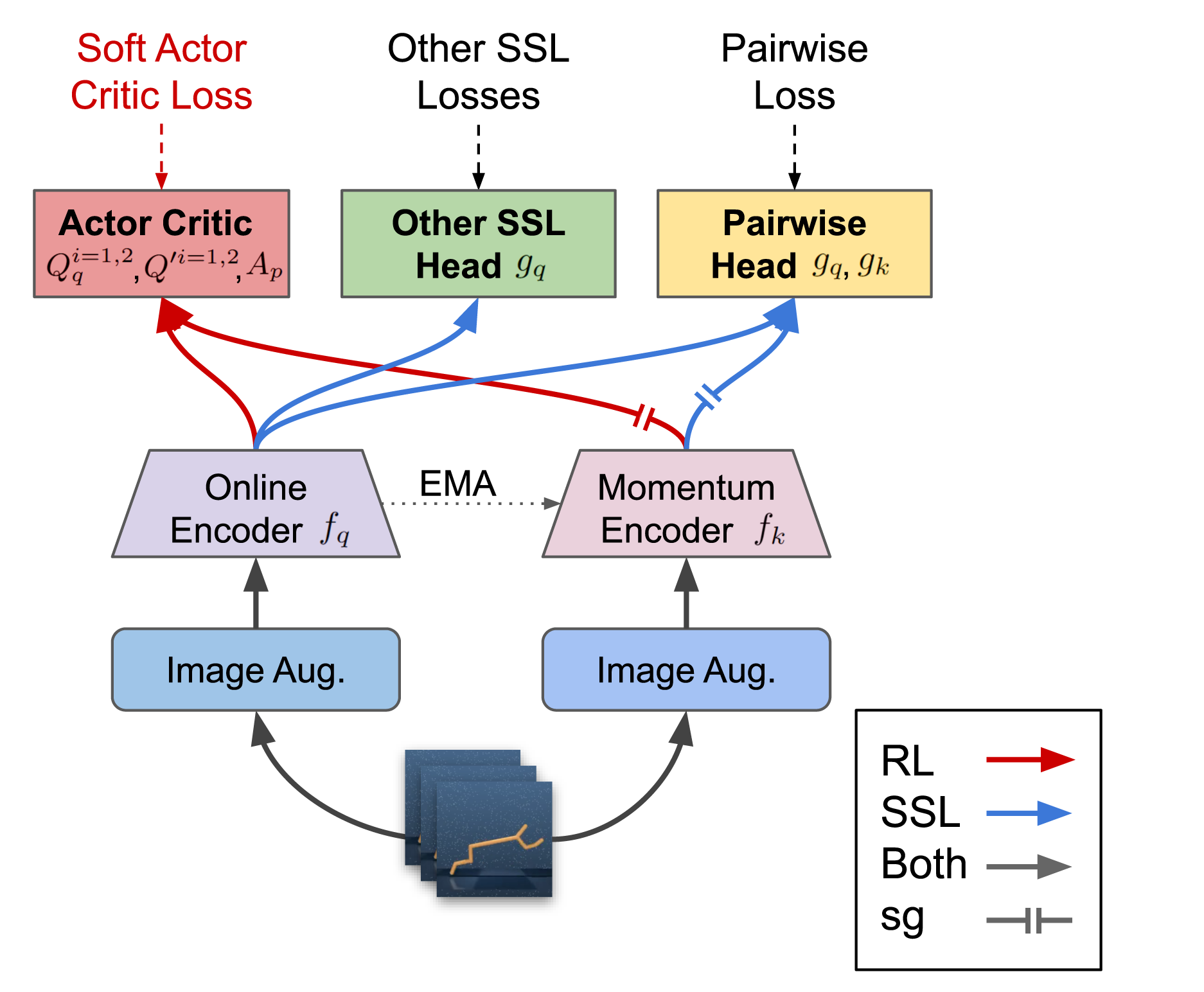
We investigate whether self-supervised learning (SSL) can improve online reinforcement learning (RL) from pixels. We extend the contrastive reinforcement learning framework (e.g., CURL) that jointly optimizes SSL and RL losses and conduct an extensive amount of experiments with various self-supervised losses. Our observations suggest that the existing SSL framework for RL fails to bring meaningful improvement over the baselines only taking advantage of image augmentation when the same amount of data and augmentation is used. We further perform an evolutionary search to find the optimal combination of multiple self-supervised losses for RL, but find that even such a loss combination fails to meaningfully outperform the methods that only utilize carefully designed image augmentations. Often, the use of self-supervised losses under the existing framework lowered RL performances. We evaluate the approach in multiple different environments including a real-world robot environment and confirm that no single self-supervised loss or image augmentation method can dominate all environments and that the current framework for joint optimization of SSL and RL is limited. Finally, we empirically investigate the pretraining framework for SSL + RL and the properties of representations learned with different approaches.
翻译:我们研究的是,自我监督的学习(SSL)能否从像素中改进在线强化学习(RL)?我们扩展了对比式强化学习框架(例如CURL),共同优化SSL和RL损失,对各种自我监督的损失进行大量实验。我们的观察表明,现有SSL的学习框架不能在基线的基础上带来有意义的改进,而只是在使用相同数量的数据和增强力时,才能利用图像增强;我们进一步进行进化搜索,以找到RL多重自我监督损失的最佳组合,但发现即使这种损失组合也未能真正超越仅使用精心设计的图像增强力的方法。通常,在现有框架下使用自我监督的损失降低了RL的性能。我们评估了多种不同环境中的方法,包括真实世界机器人环境,并证实没有单一的自我监督损失或图像增强方法能够控制所有环境,而且目前SL和RL的联合优化框架是有限的。最后,我们用SL+RL的不同方法以及所学的属性,对SL的预培训框架进行了实验性研究。